Zeptojoule Computing:
Superconducting adiabatic logic for scalable energy-efficient hardware
Committee members:
Neil Gershenfeld, Director, Center for Bits and Atoms, MIT
Karl K. Berggren, Faculty Head, EE and Julius A. Stratton Professor in Electrical Engineering and Physics, MIT
Vivienne Sze, Professor in Electrical Engineering and Computer Science, MIT

Billions of transistors switching
billions of times per second
consume a lot of the power
Transistors can't keep shrinking
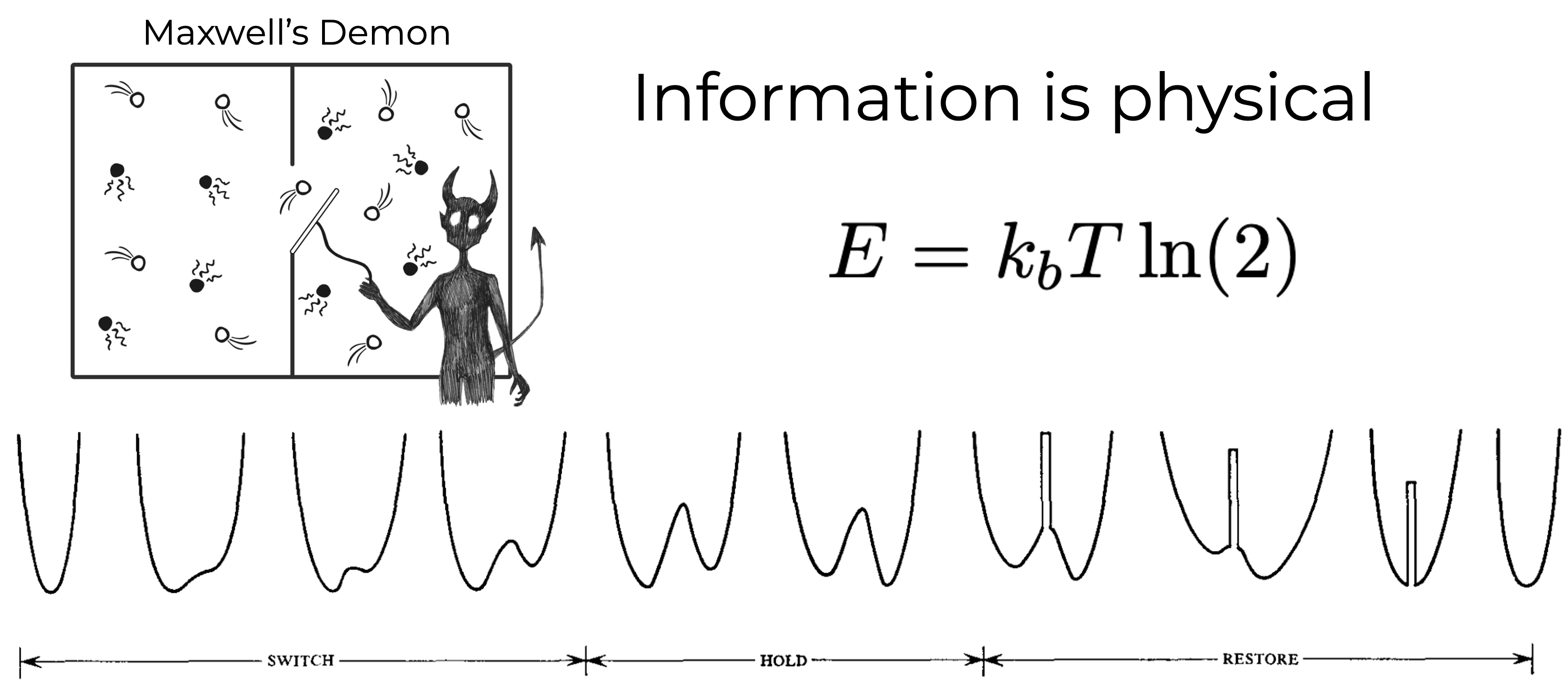
Thermodynamic cost of computation

Landauer's limit: every irreversible bit operation must dissipate at least a few zJ of energy
Adiabatic Quantum Flux Parametron (AQFP):
digital logic near Landauer's limit
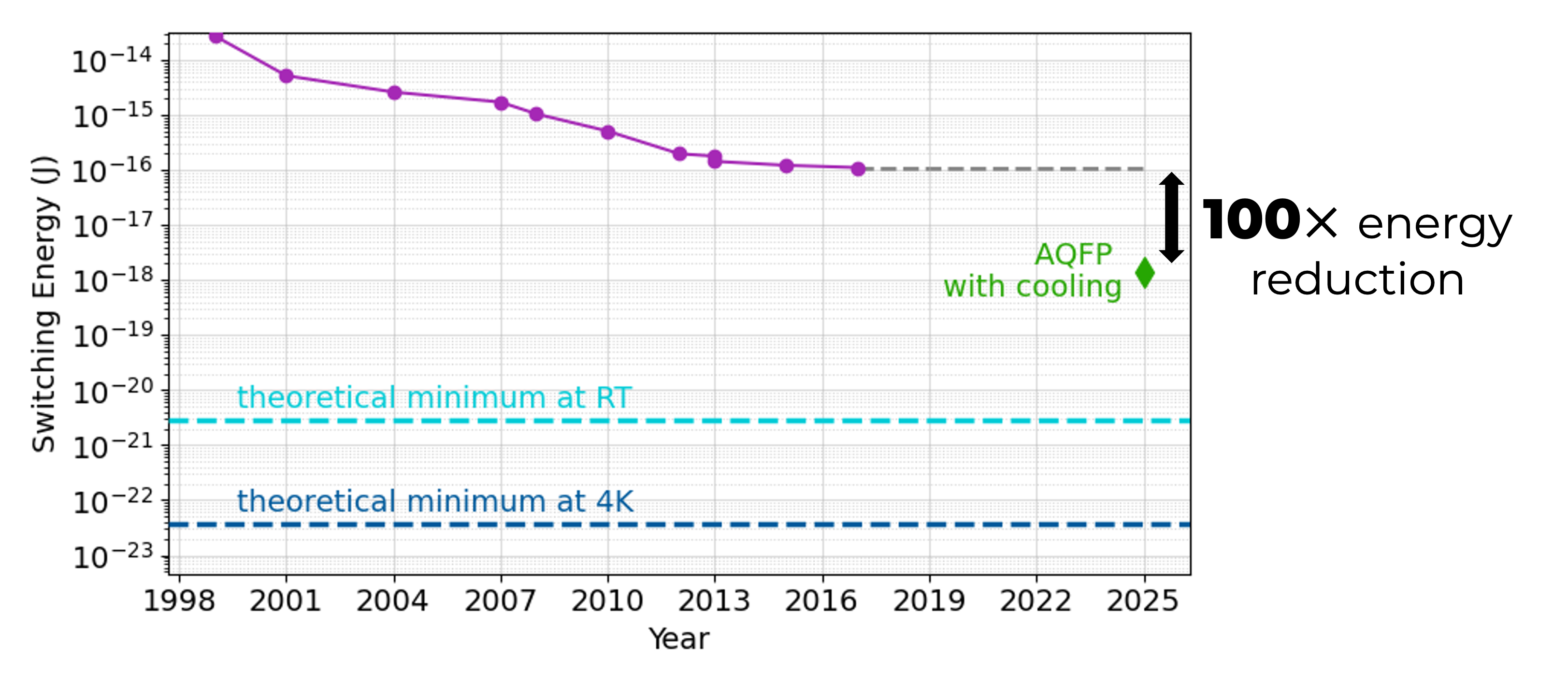
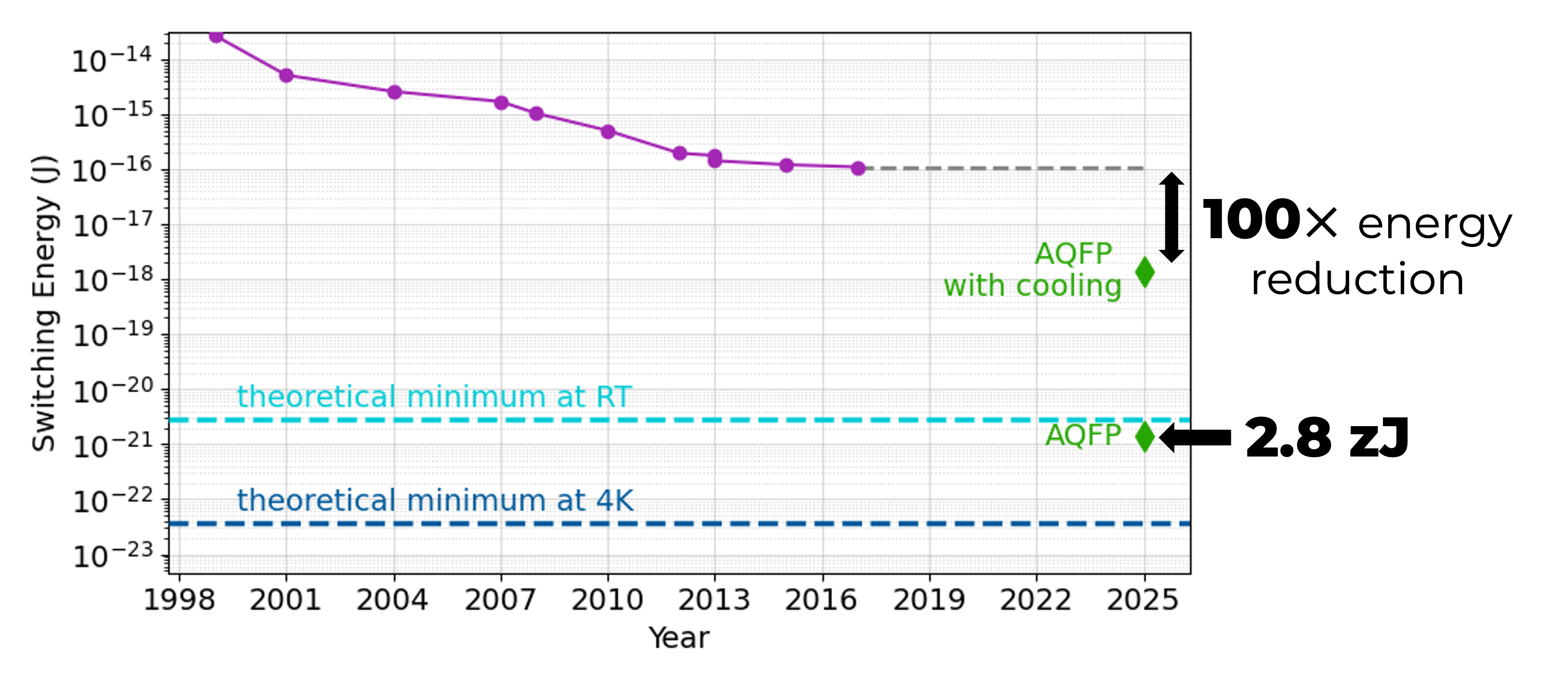
Adiabatic Quantum Flux Parametron (AQFP):
digital logic near Landauer's limit
But there's a big leap from devices to datacenters




Devices
Gates & Circuits
Memory & Compute
Microarchitecture
Architecture
First, a bit of historical context . . .
Superconducting logic has a long history of promises
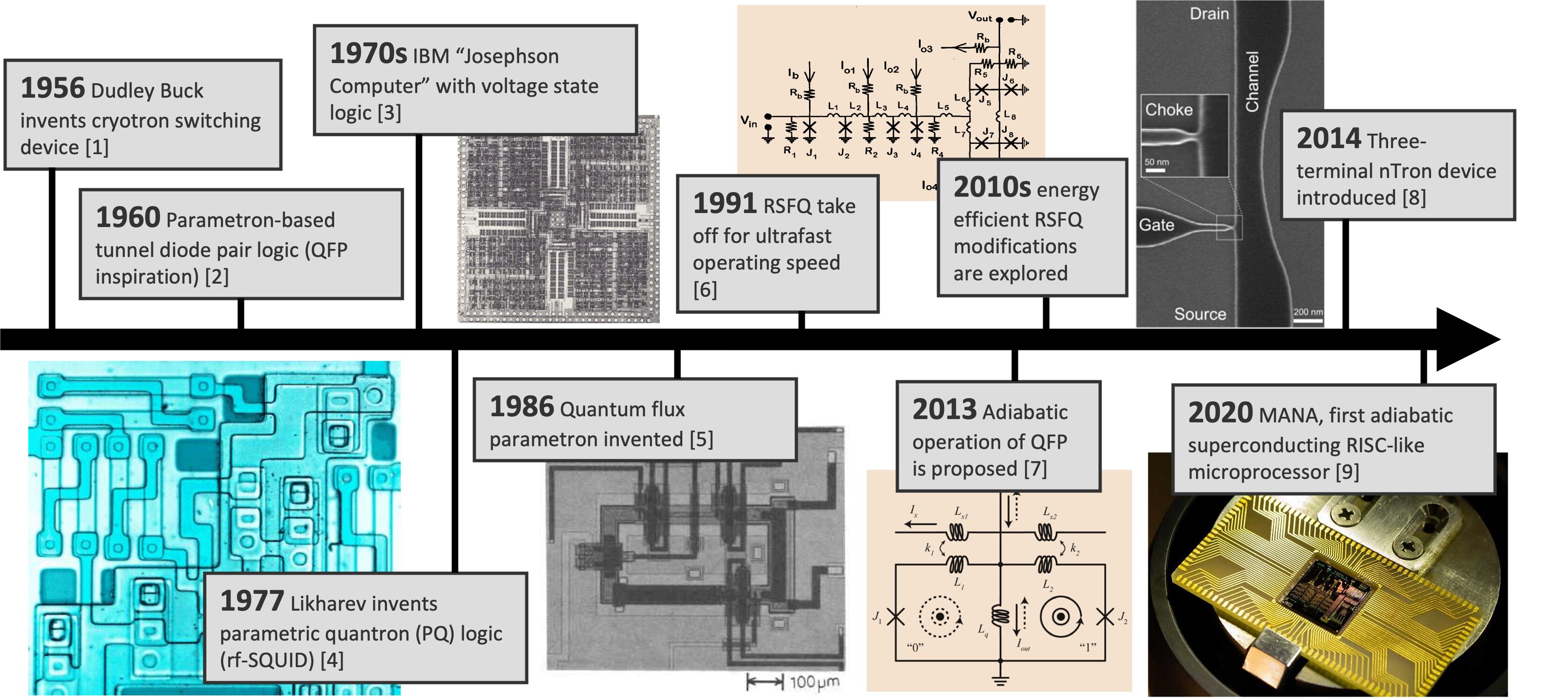

- Lead-alloy Josephson junctions were unreliable
- Resistive logic was high energy
- Moore's law competition
Rapid Single Flux Quantum (RSFQ)
- Extreme speed – 770 GHz demonstration
- Switching energy comparable to CMOS
- Difficulty scaling power delivery
- Magnetic flux trapping
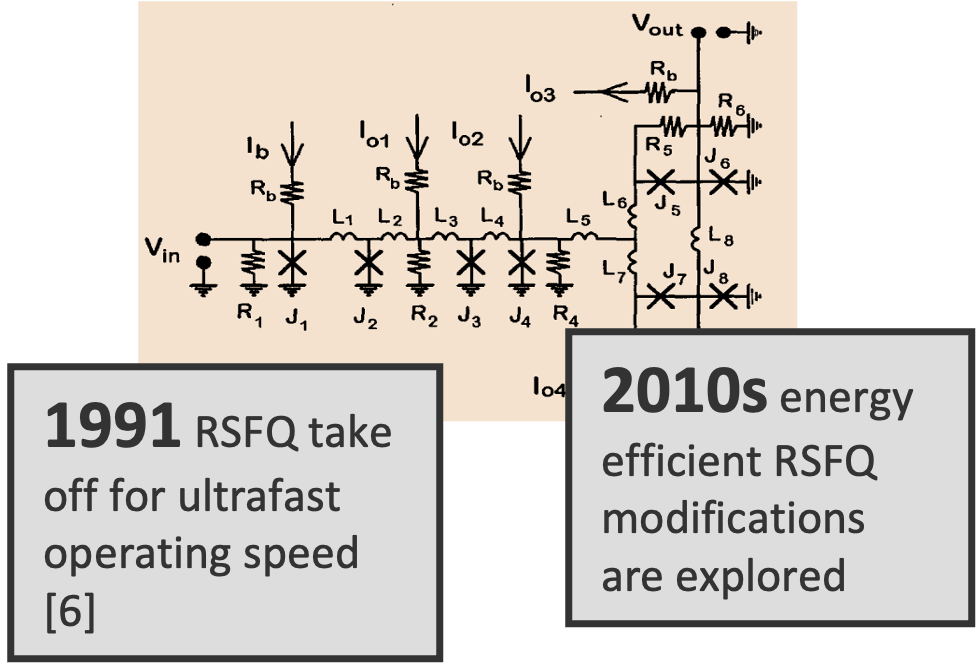
Adiabatic Quantum Flux Parametron (AQFP)
- Switching energy near thermodynamic limit
- ~5 GHz clock speed
- Improved tolerance to flux trapping
- Low drive strength and fanout
- Multi-phase clocking requirement
- Deep pipelines increase latency
Why now for AQFP?
Energy is now the bottleneck
CMOS scaling is slowing
Fabrication has matured
Cryogenic ecosystems exist
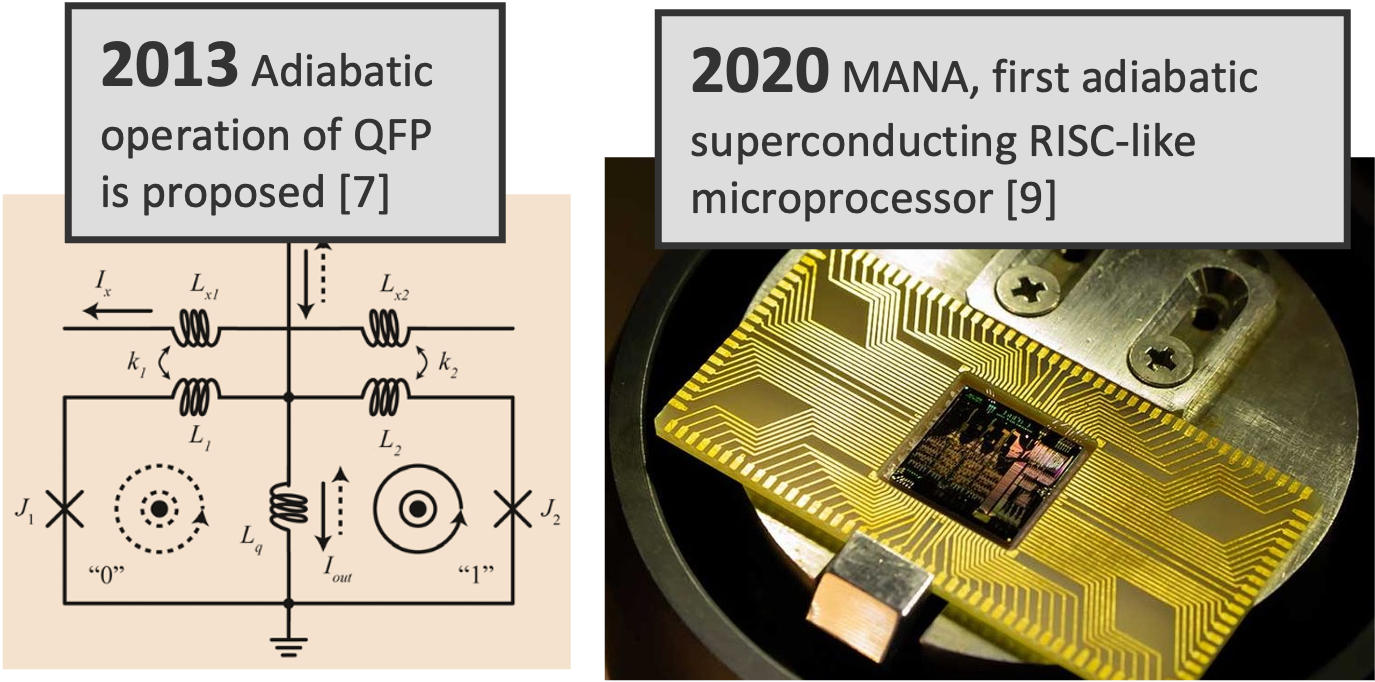
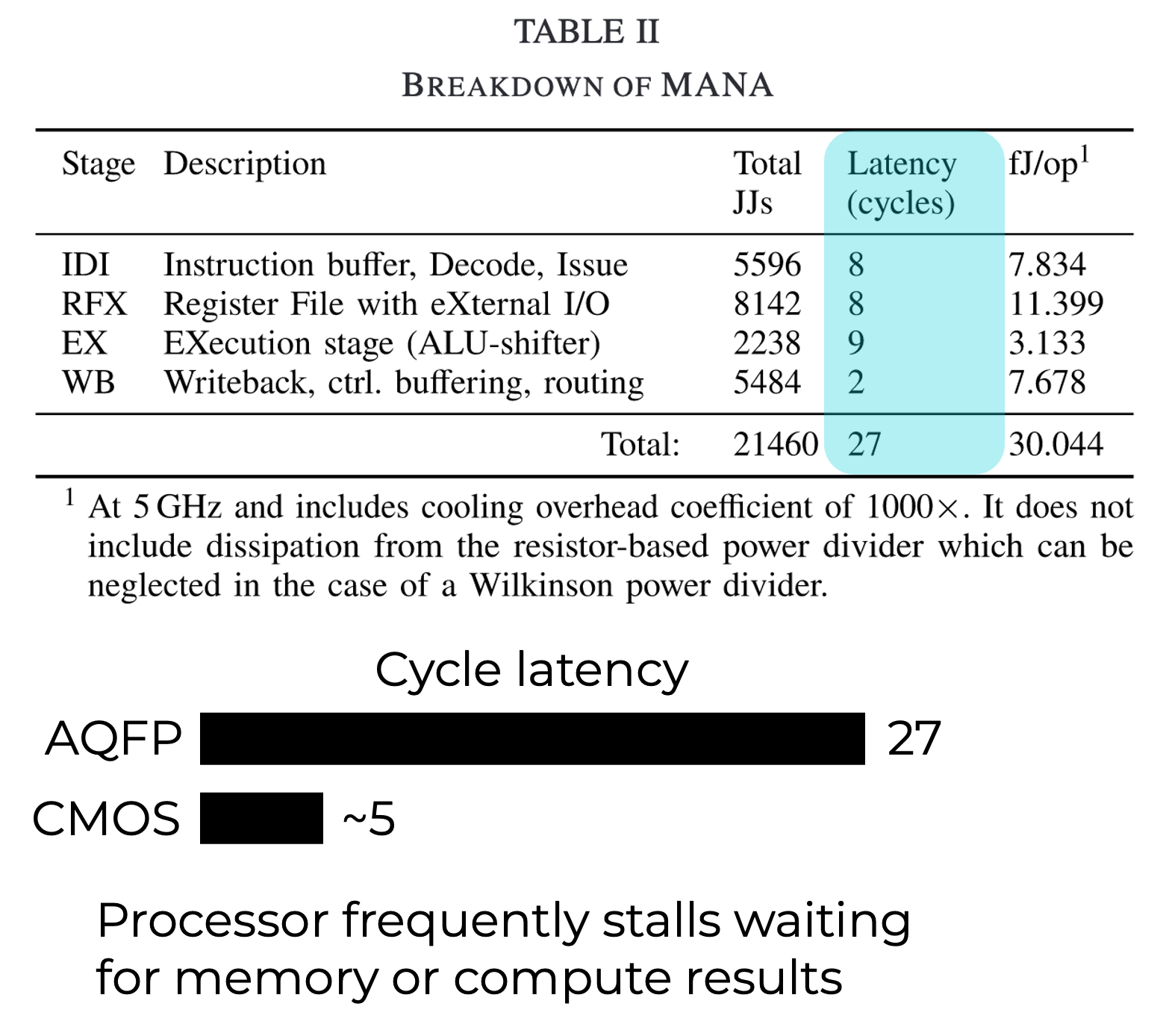
AQFP 4-b RISC-like microprocessor
Largest AQFP system demonstrated to date
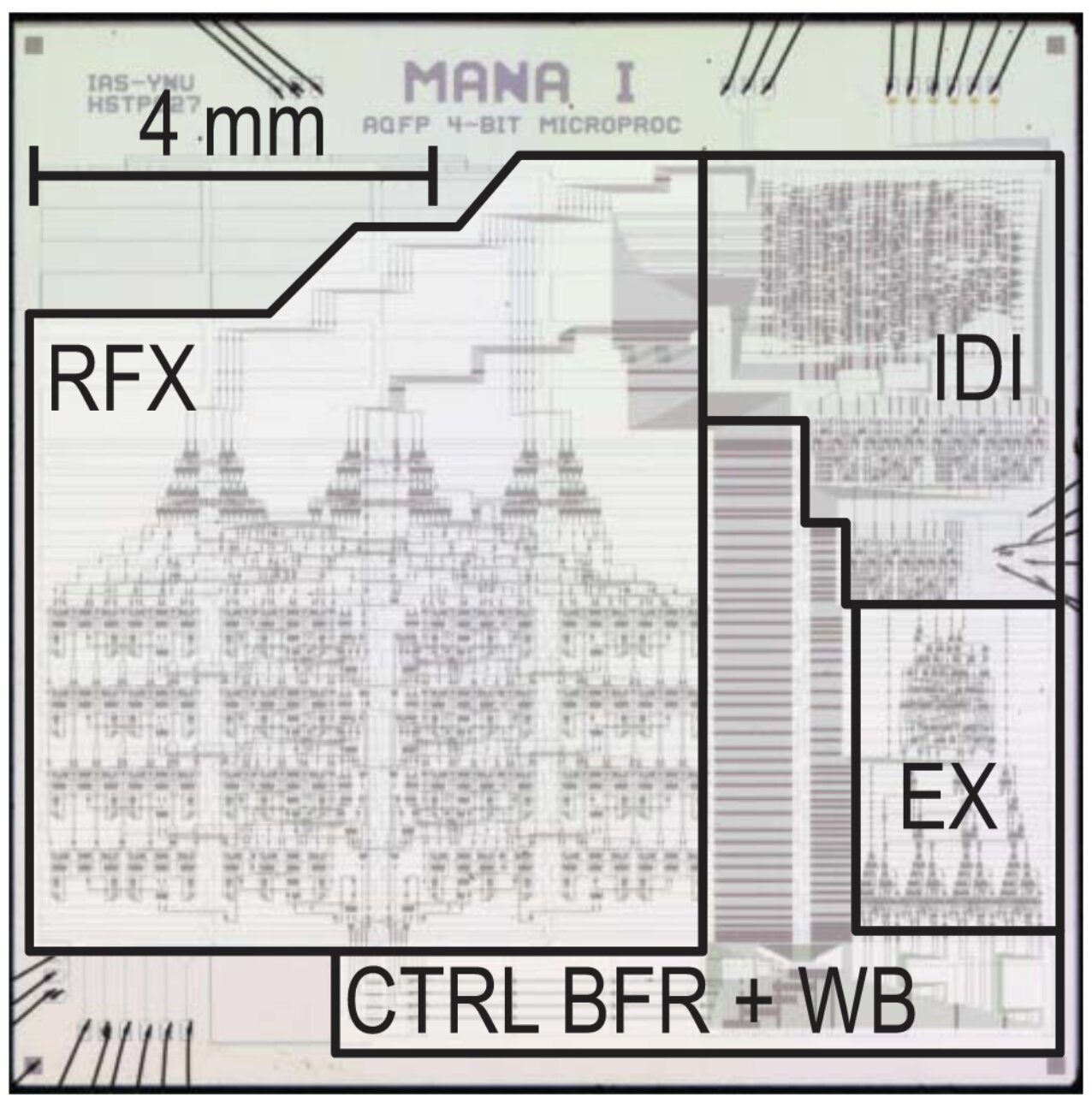
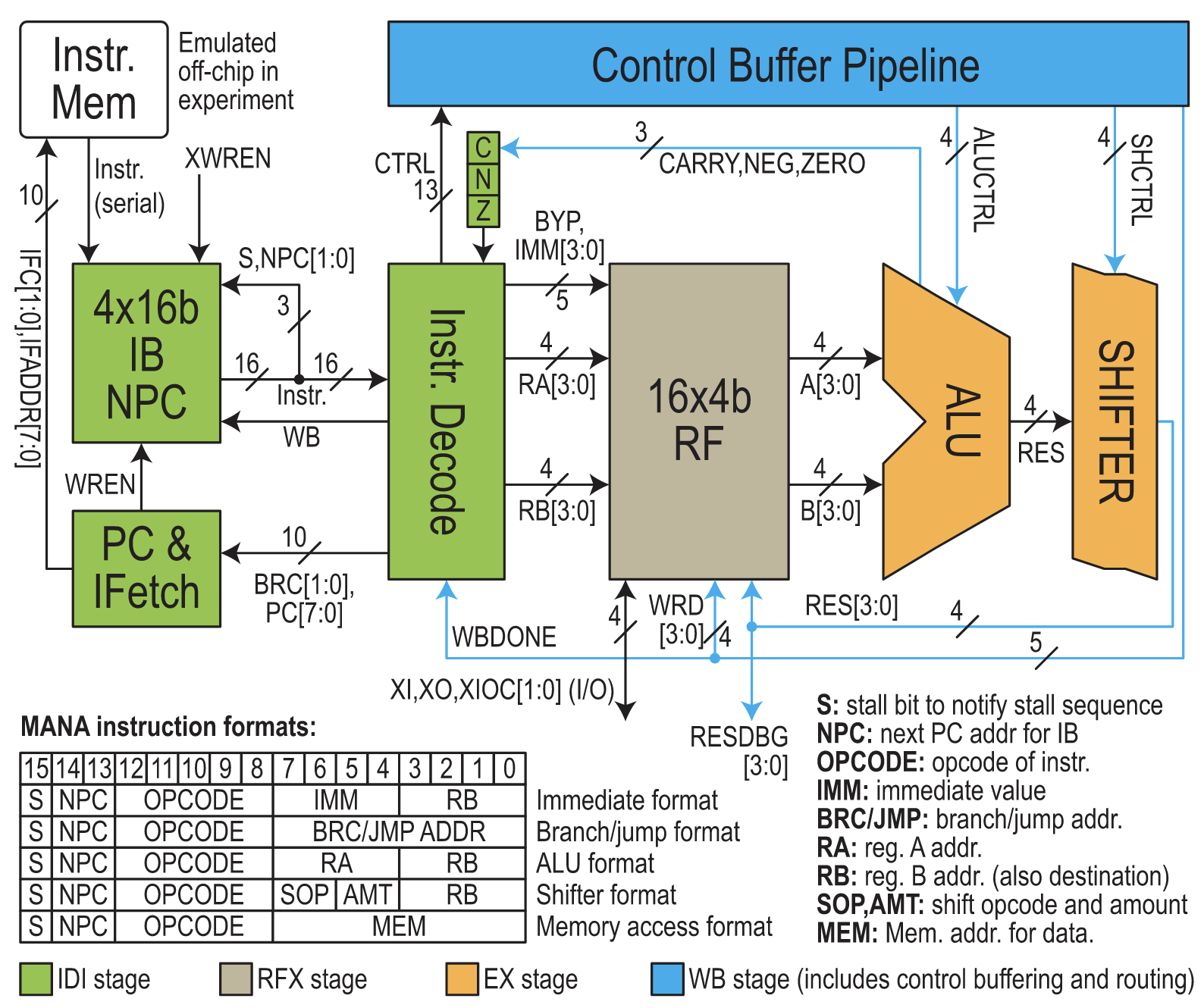
CMOS architecture mismatched to AQFP

How do we design computing systems that
exploit AQFP physics
while maintaining efficiency and performance?
Device
What is an AQFP?

AQFP energy landscape


AQFP energy landscape
AQFP energy landscape

Biases
Inductors
Josephson Junctions
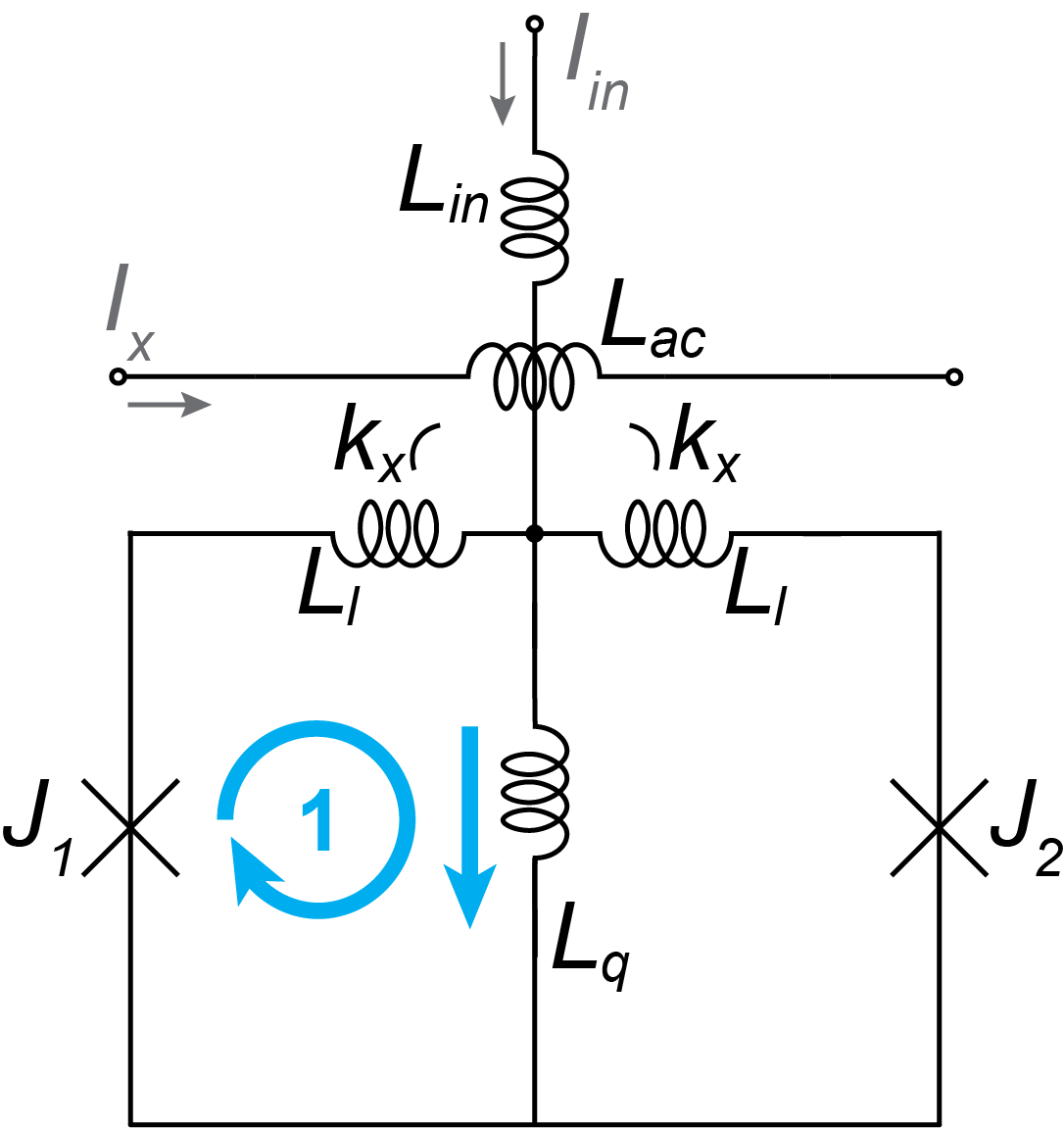
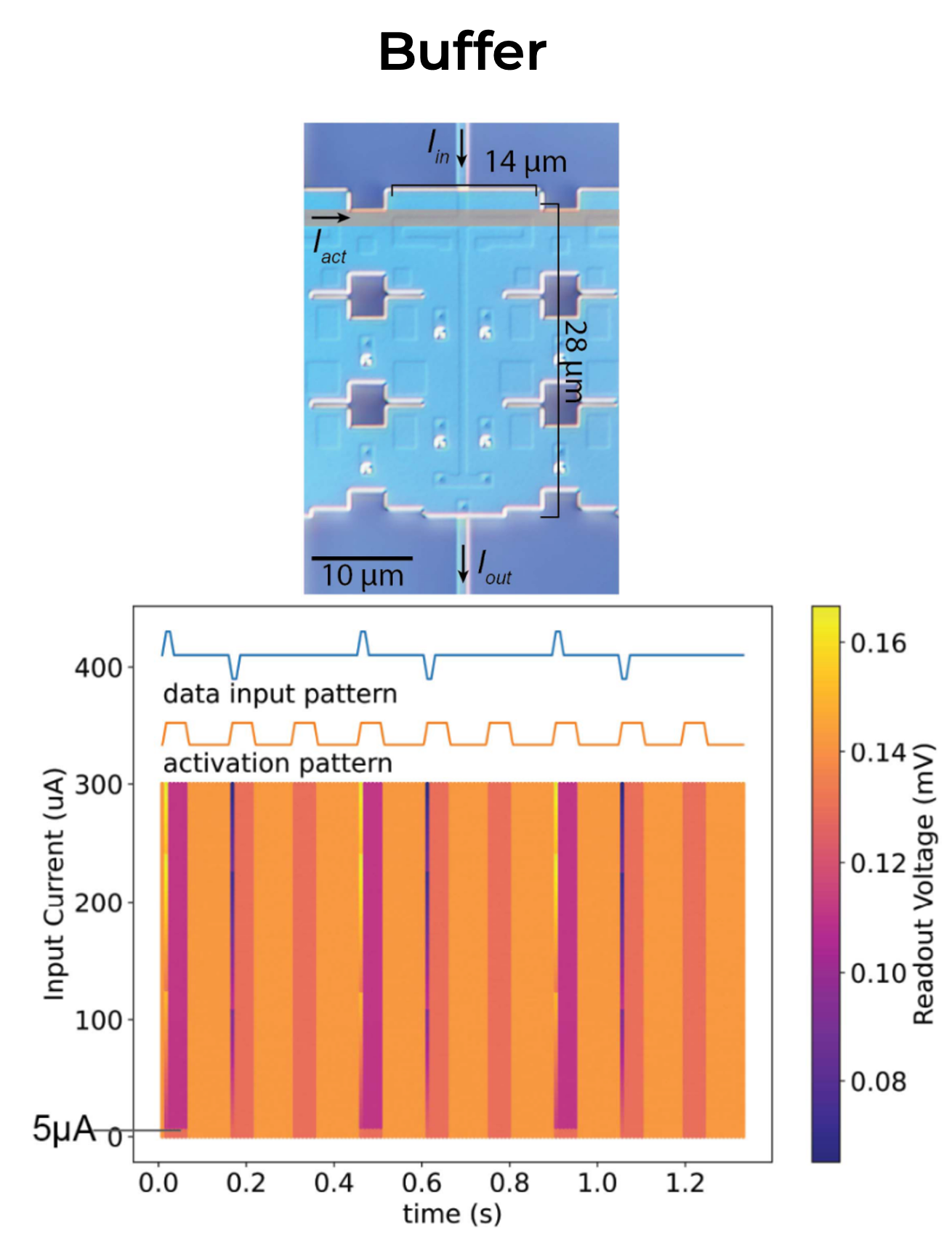
AQFP as a digital logic switch
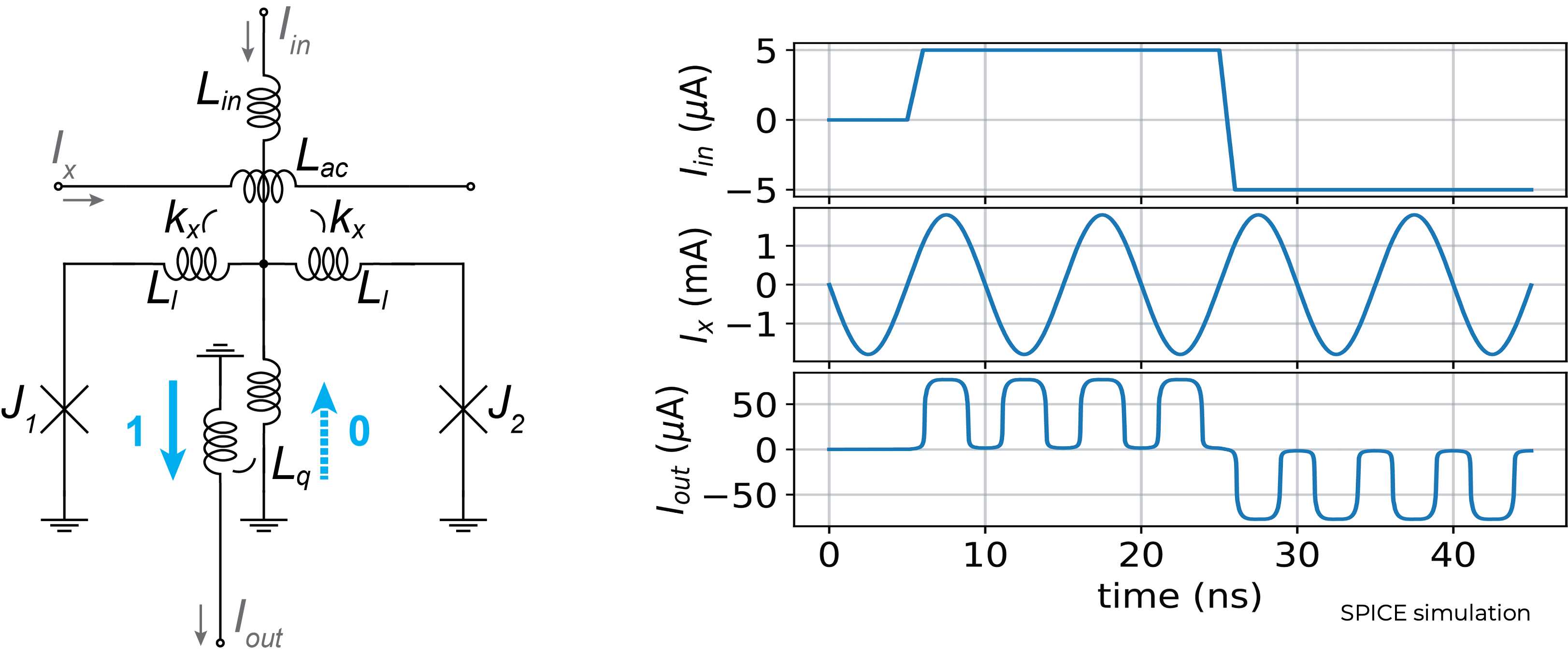
Combinational logic gates
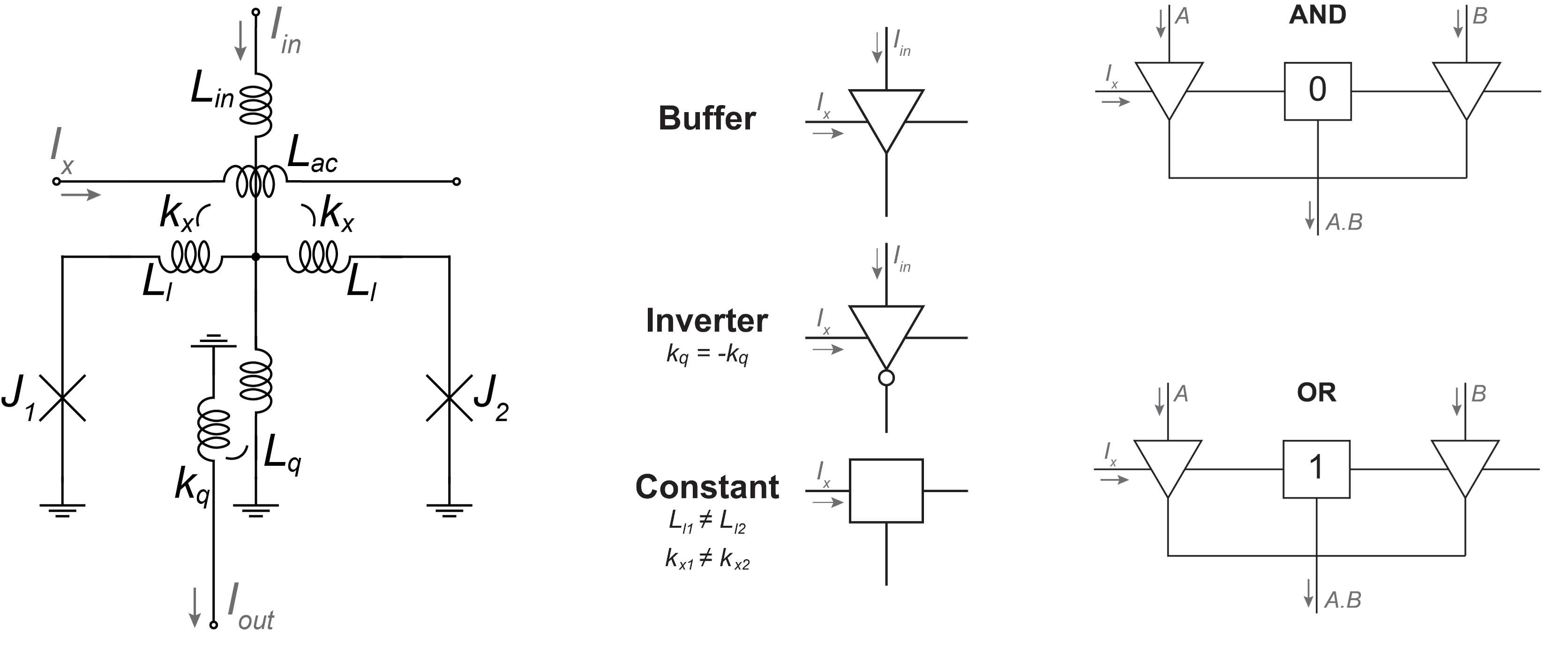
AQFP is a two-terminal device
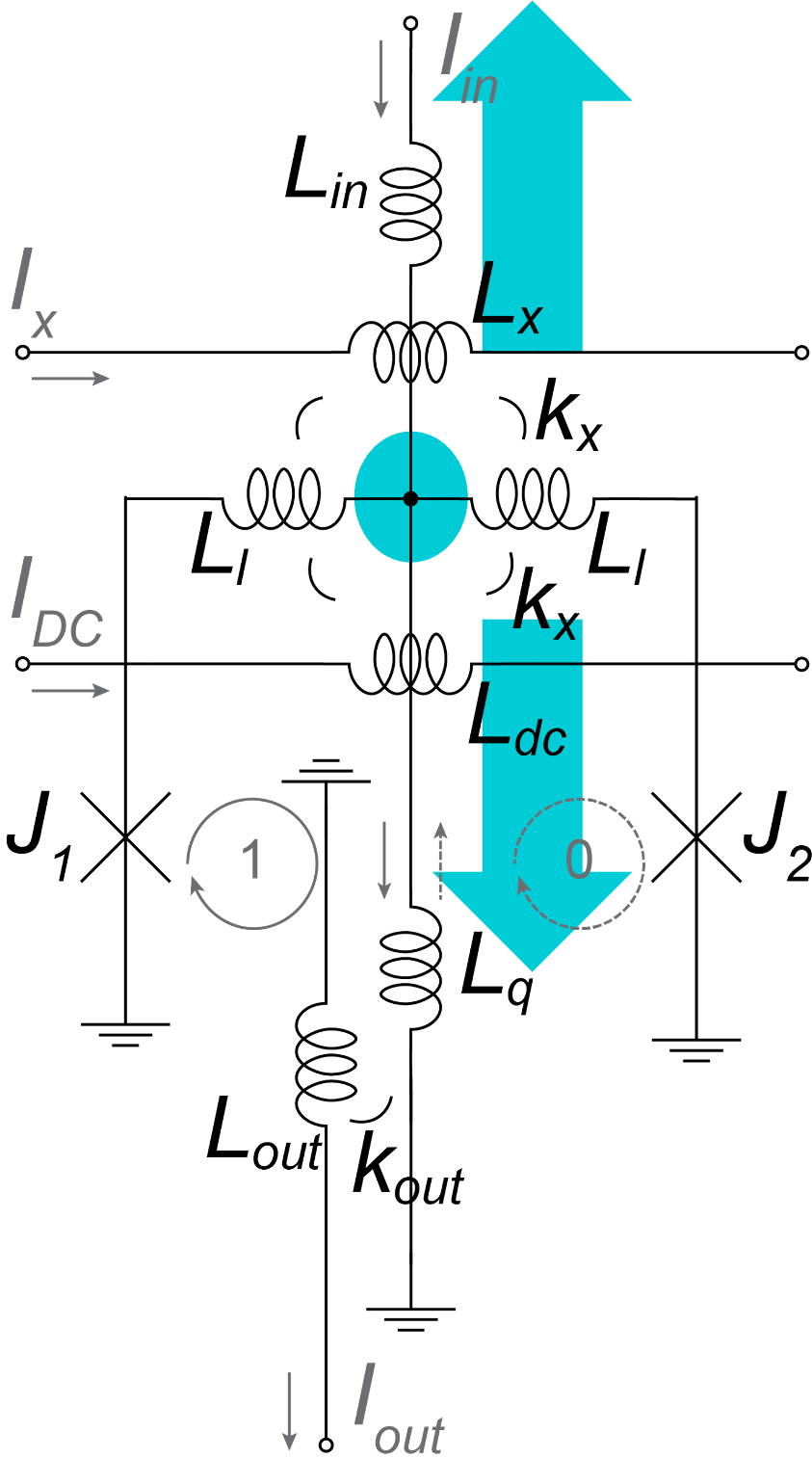
n-phase clock propagates data along AQFP buffer chain

n = 3

n = 2
n must ≥ 3 for correct data propagation
4-phase clocking with AC and DC bias
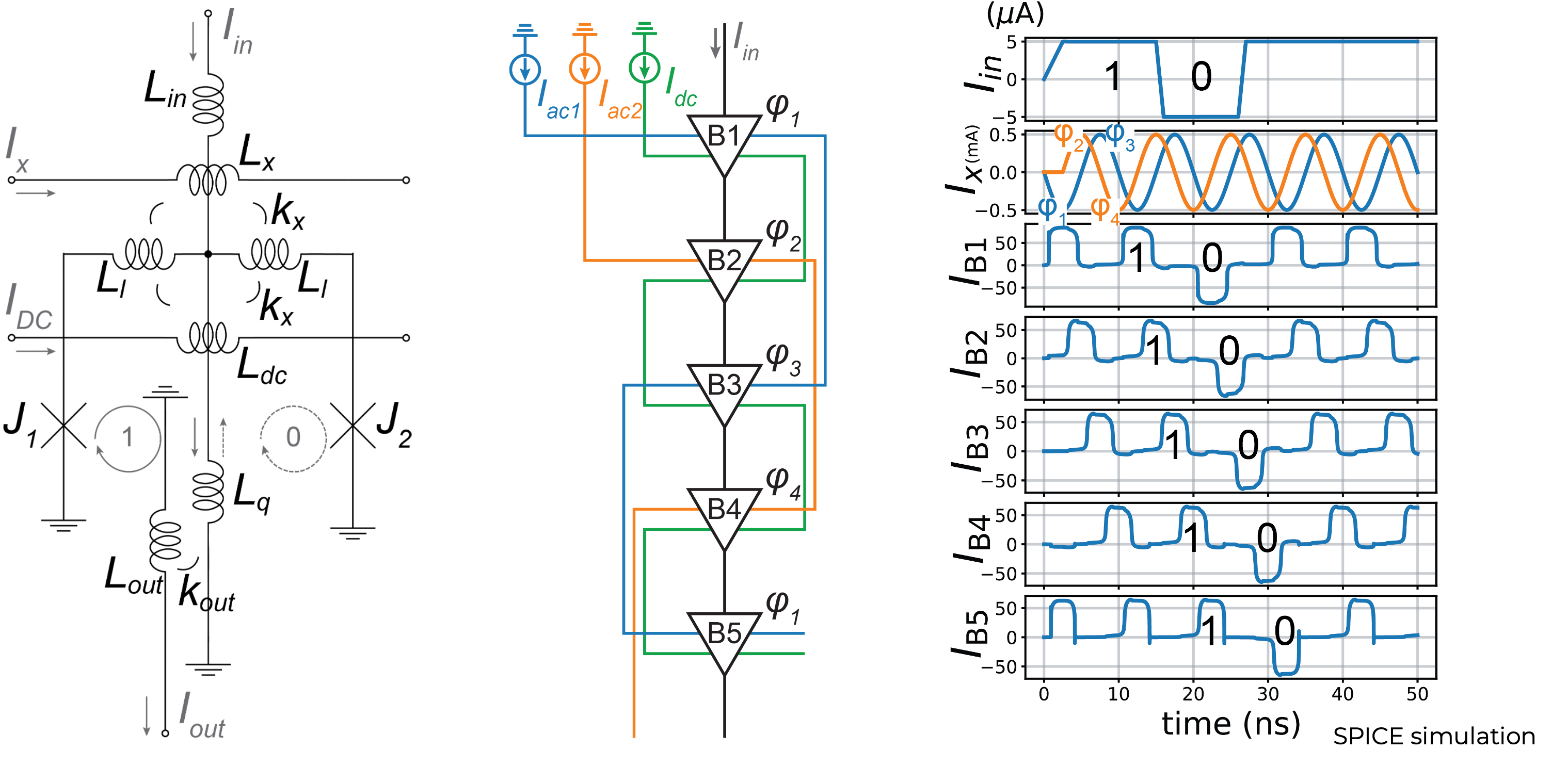
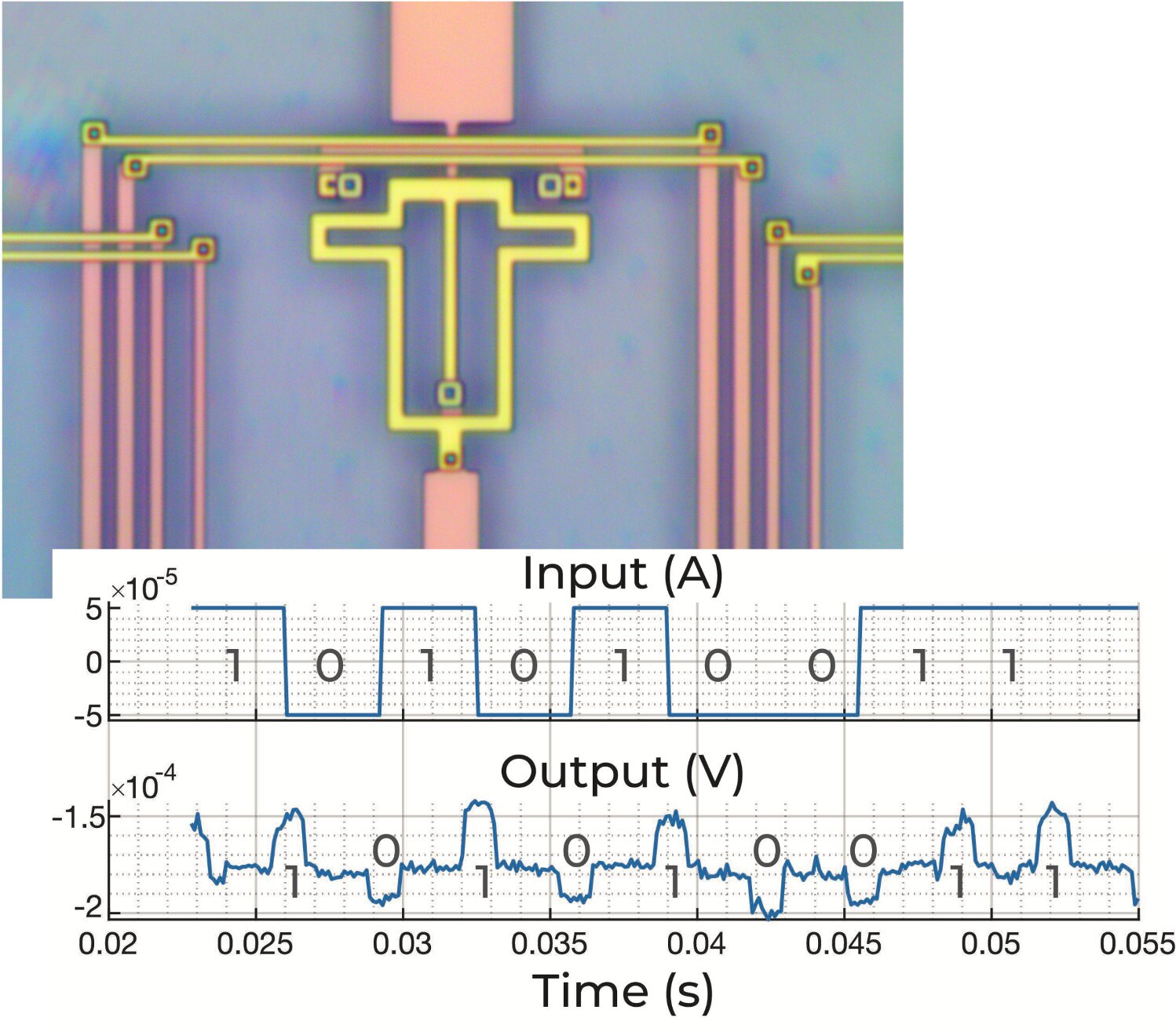
Experimental AQFP measurement
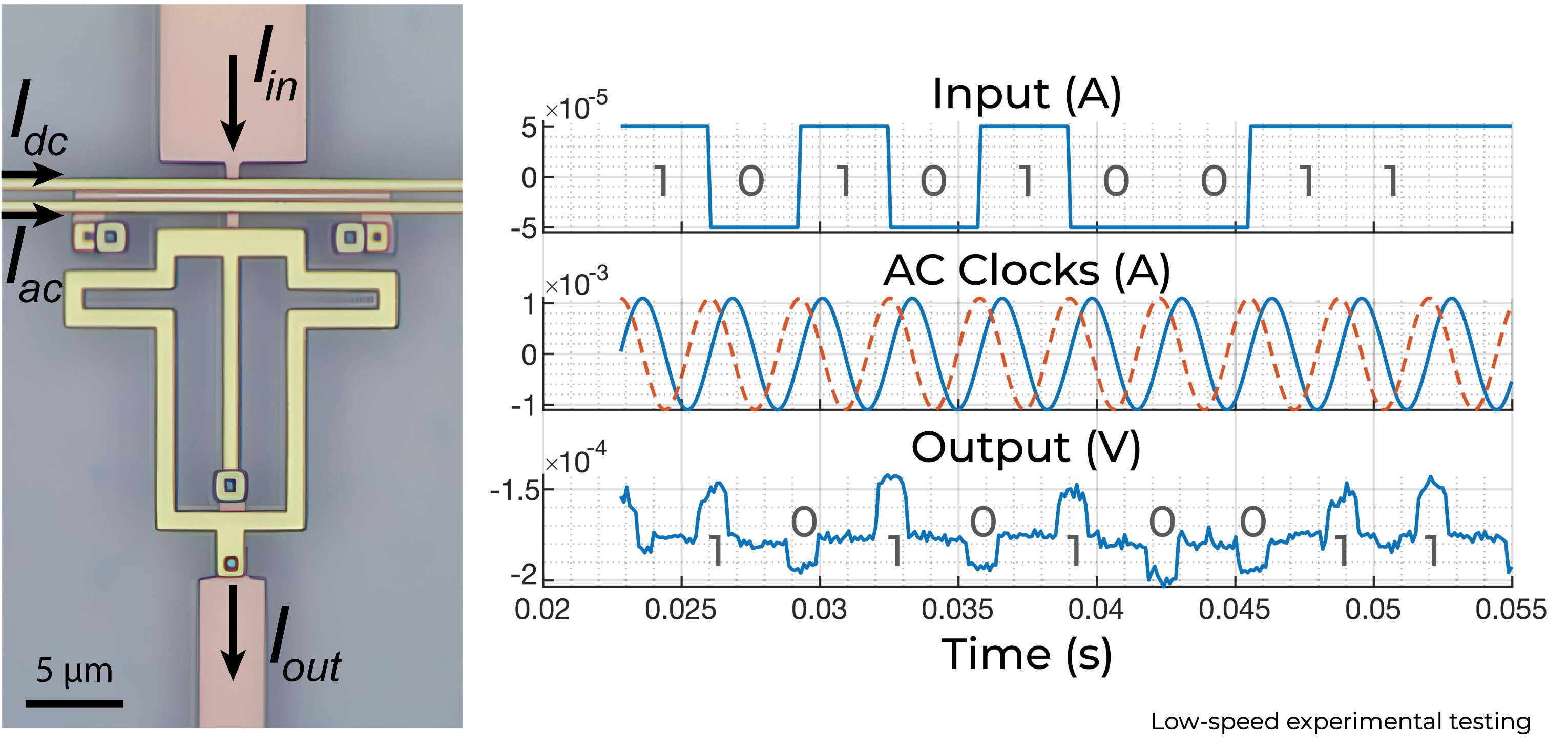
5.8 fJ/switch upper bound
On-chip energy at 4 K
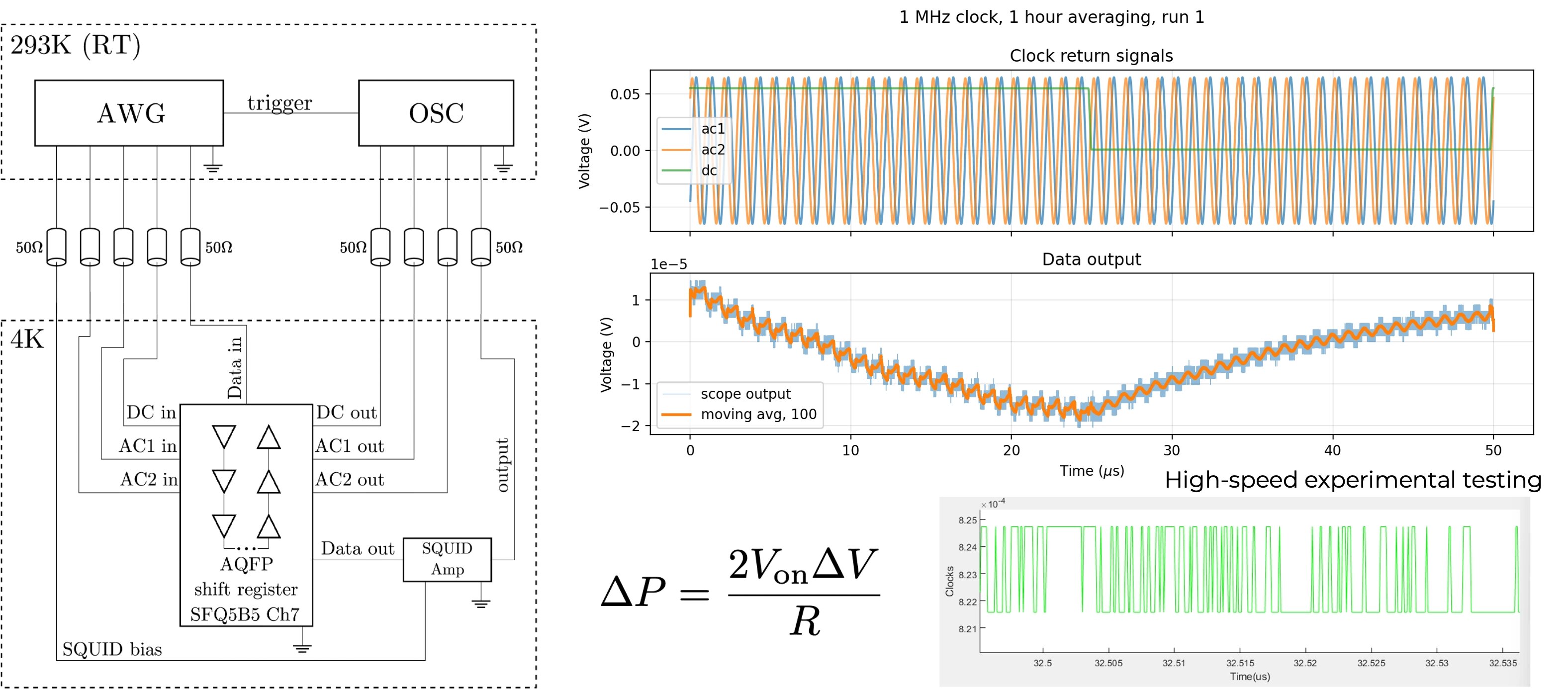
0.58 zJ/switch simulated energy dissipation
On-chip energy at 4 K
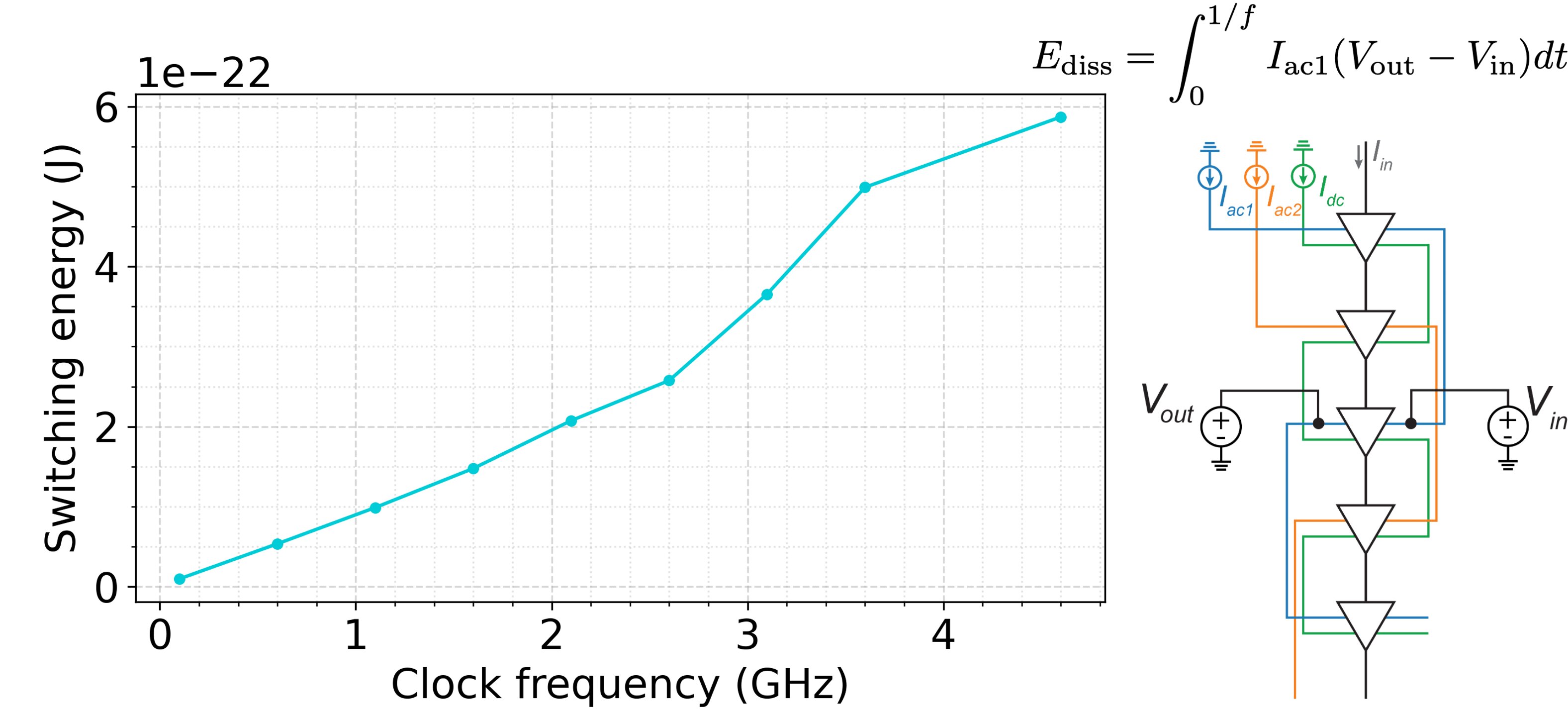
Gates & Circuits
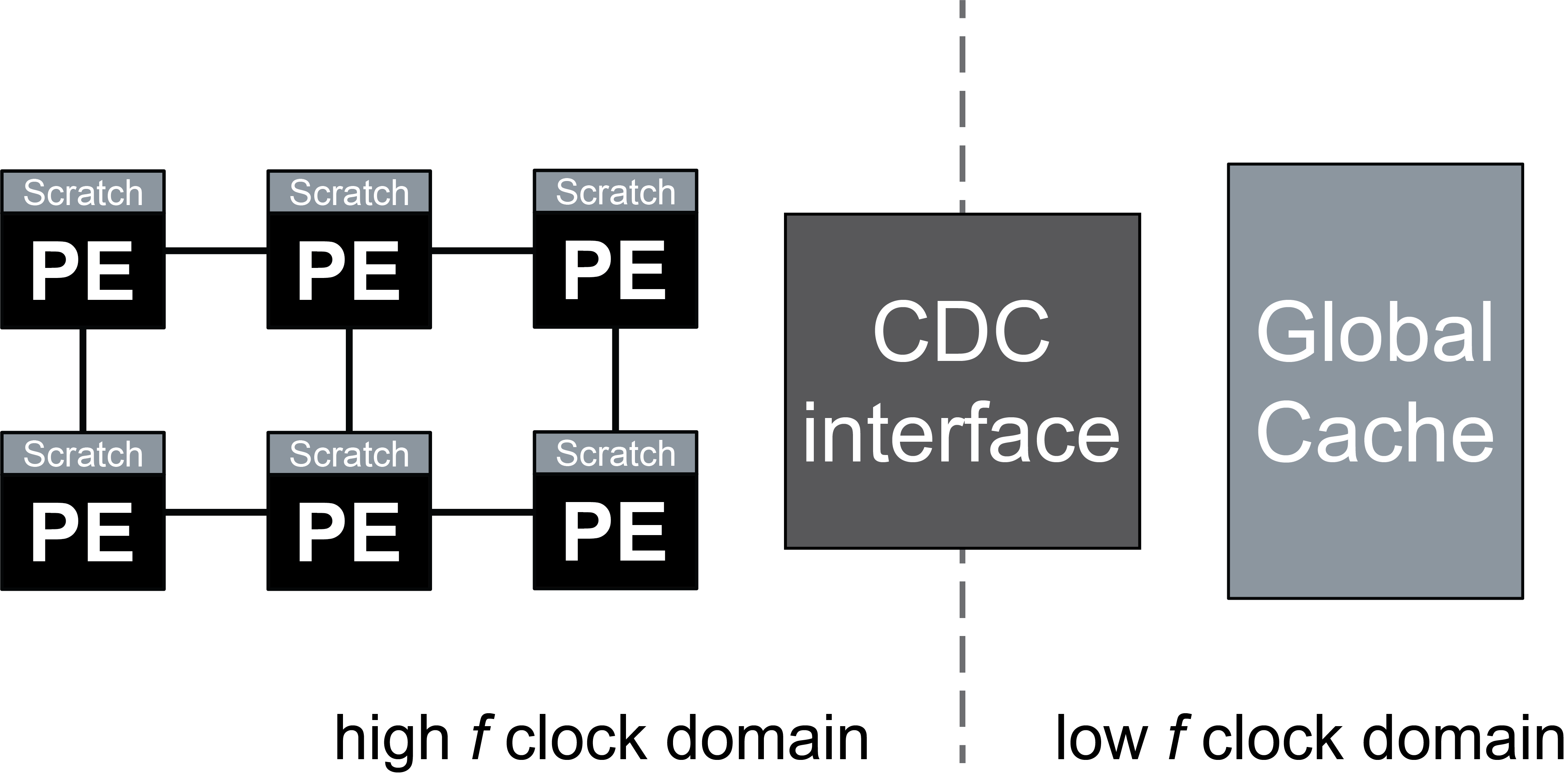
How can we relax AQFP's rigid timing constraints to enable scalable systems with clock domain crossings and multi-chip architectures?

Data arrival must be aligned with clock phase

Weak constant AQFP
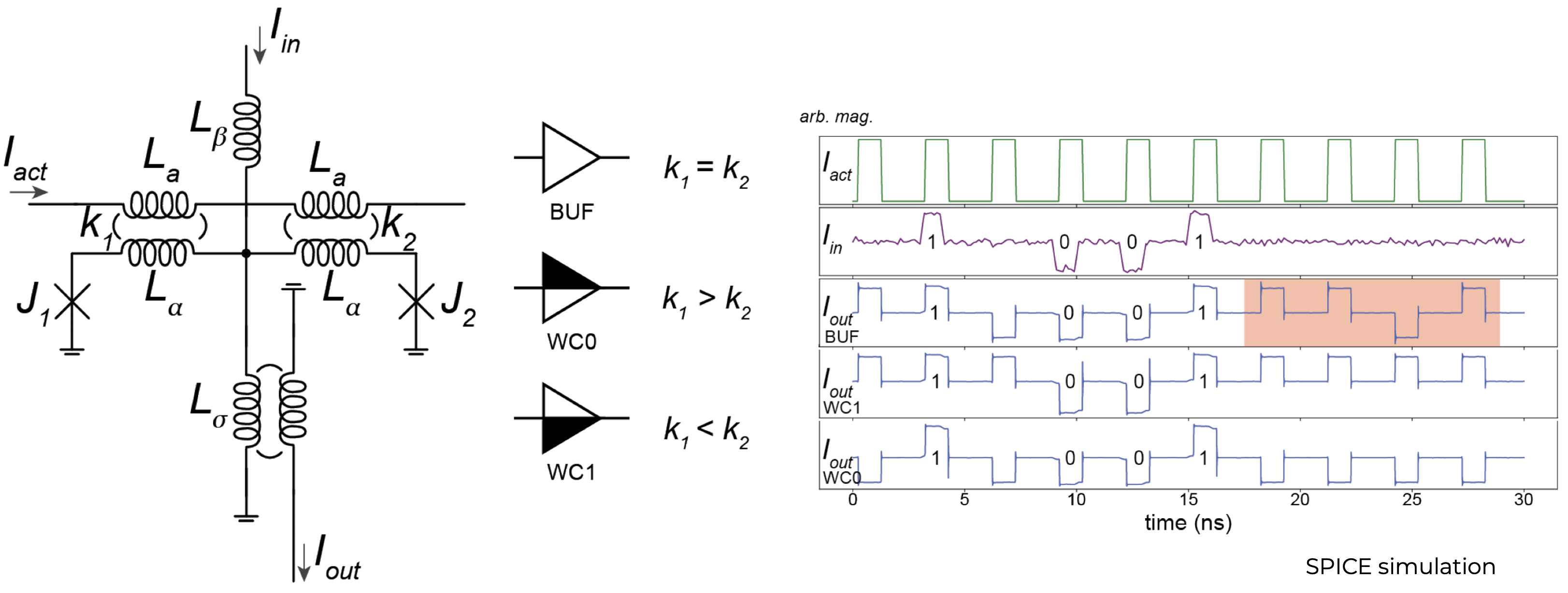
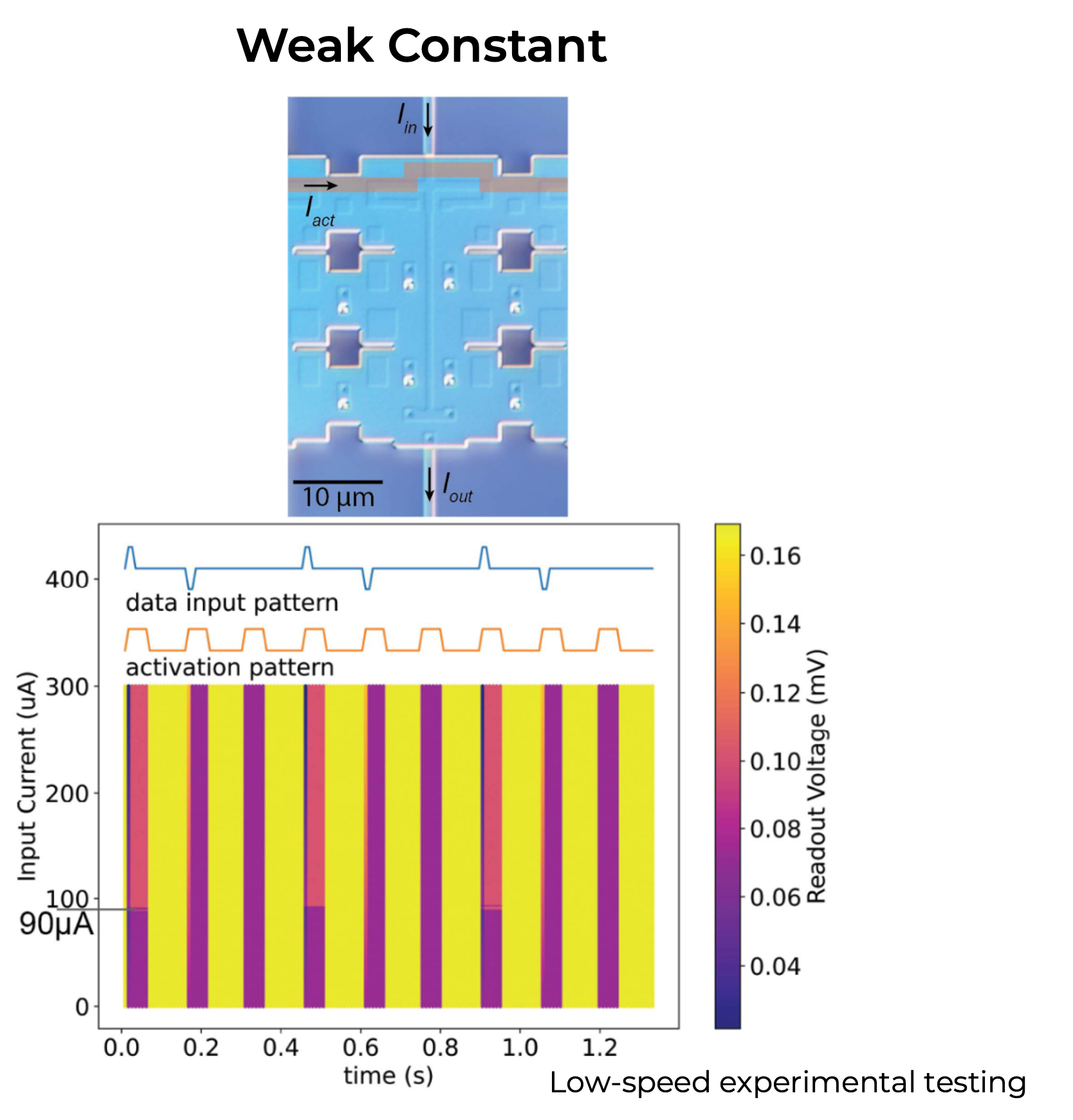
AQFP phase synchronizer
Data arrives on unknown phase and is propagated to known output phase
Phase synchronizer summary
Contributions
- Weak constant cell introduces a controllable logic threshold for AQFP inputs
- First AQFP phase synchronizer, enabling phase-agnostic data propagation
- Establishes key circuit primitives for clock domain crossing (CDC), chip-to-chip AQFP communication, and asynchronous AQFP logic
Future Work
- Optimize phase synchronizer design to reduce input drive requirements
- Design and demonstrate a complete AQFP clock domain crossing interface
- Characterize metastability limits and timing margins of the phase synchronizer
Memory & Compute Modules
How can we design on-chip memory optimized for a given workload or application?

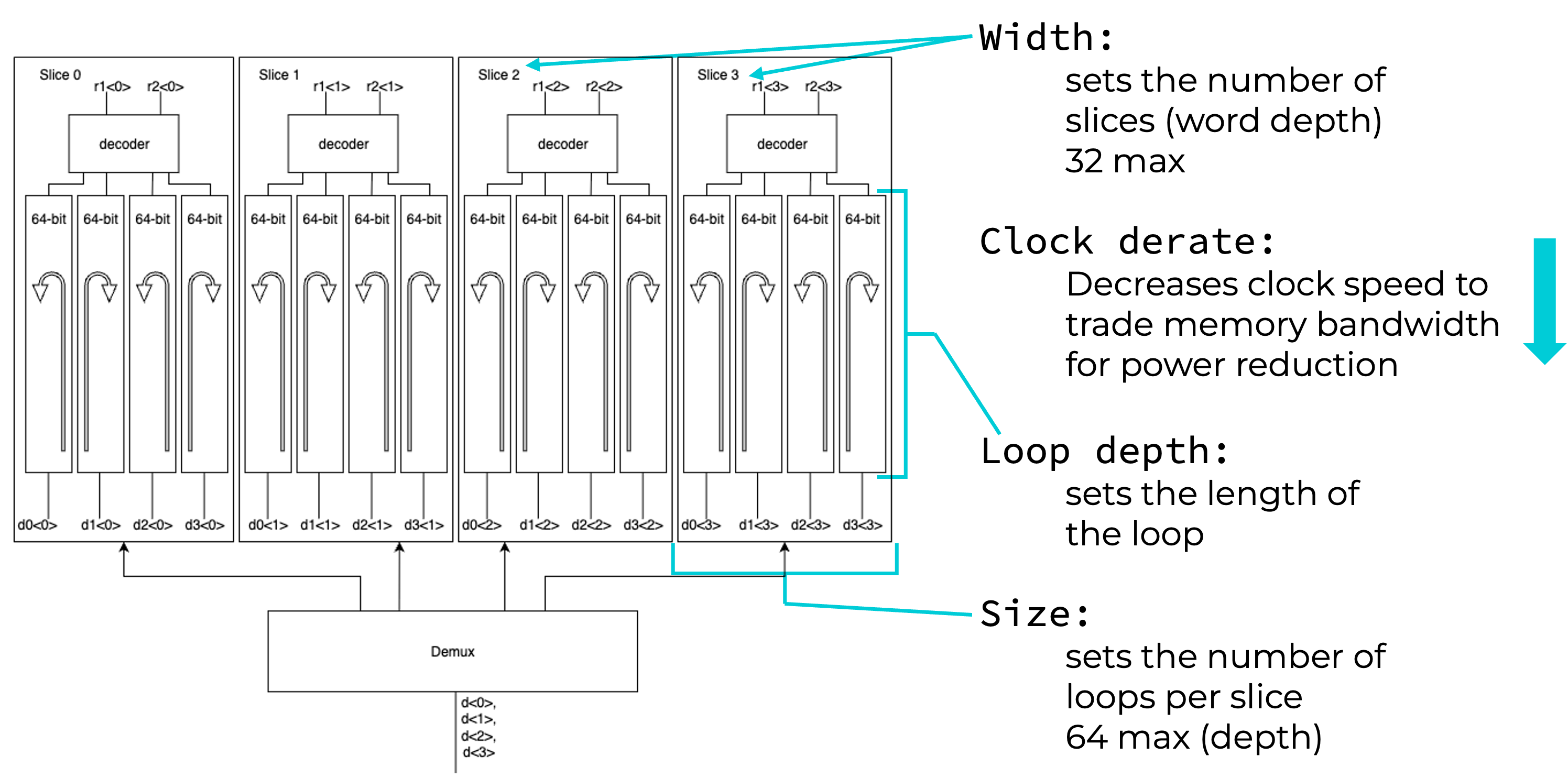
Memory tailored to device physics and applications
- Serial memory storage can decrease device count per bit stored
→ increase memory density - AI workloads have very predictable memory access patterns
→ serial memory does not limit throughput


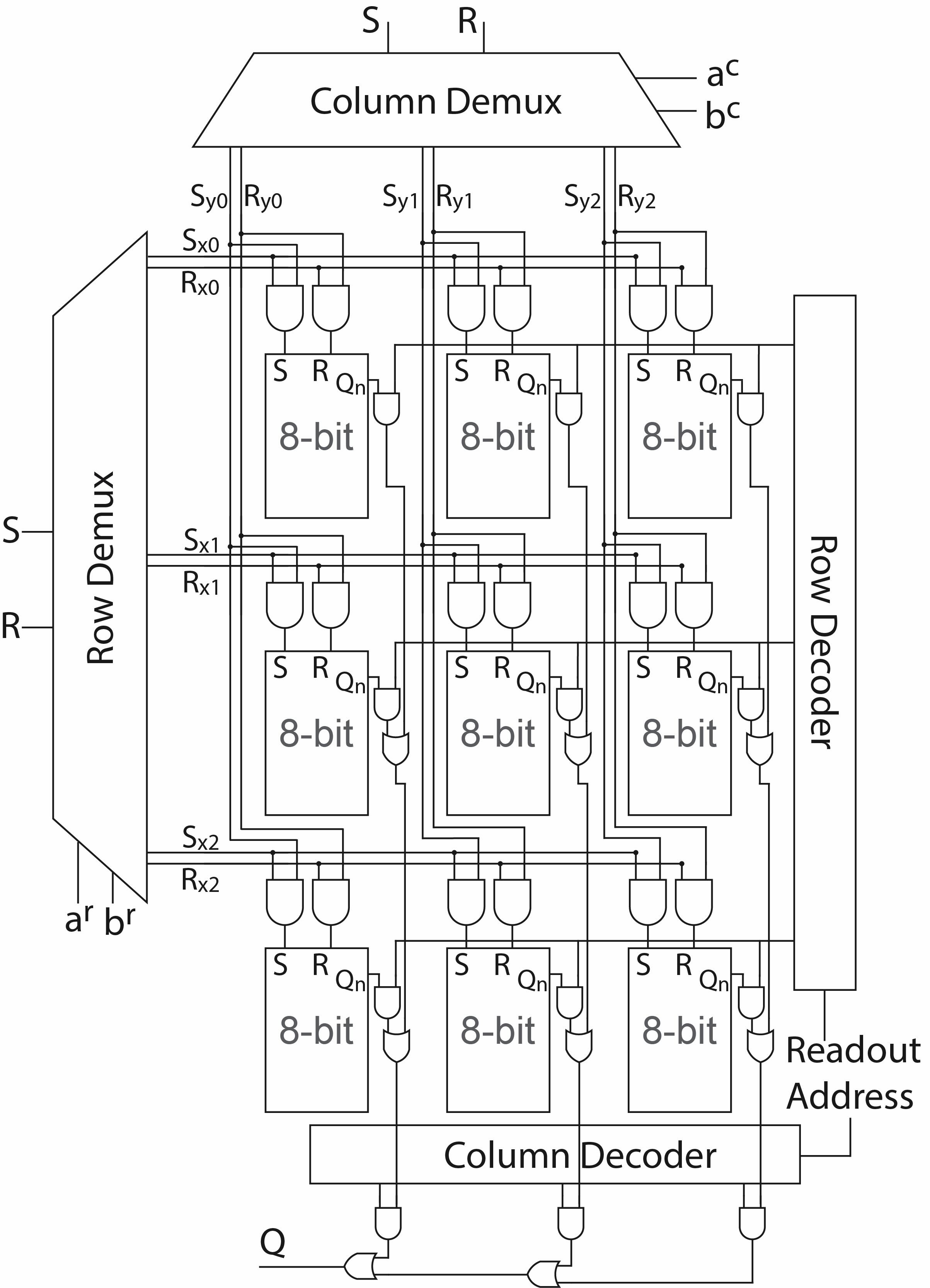
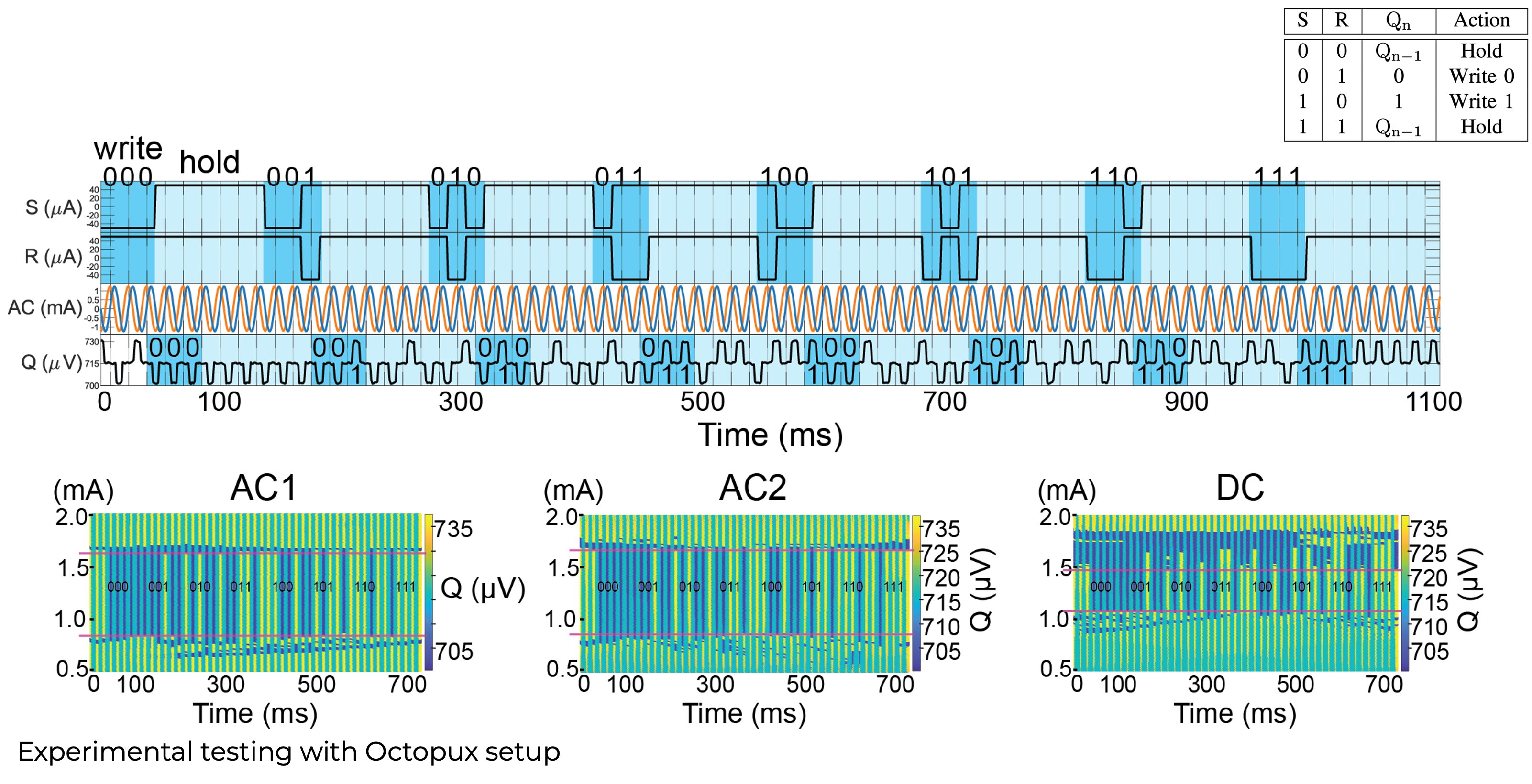
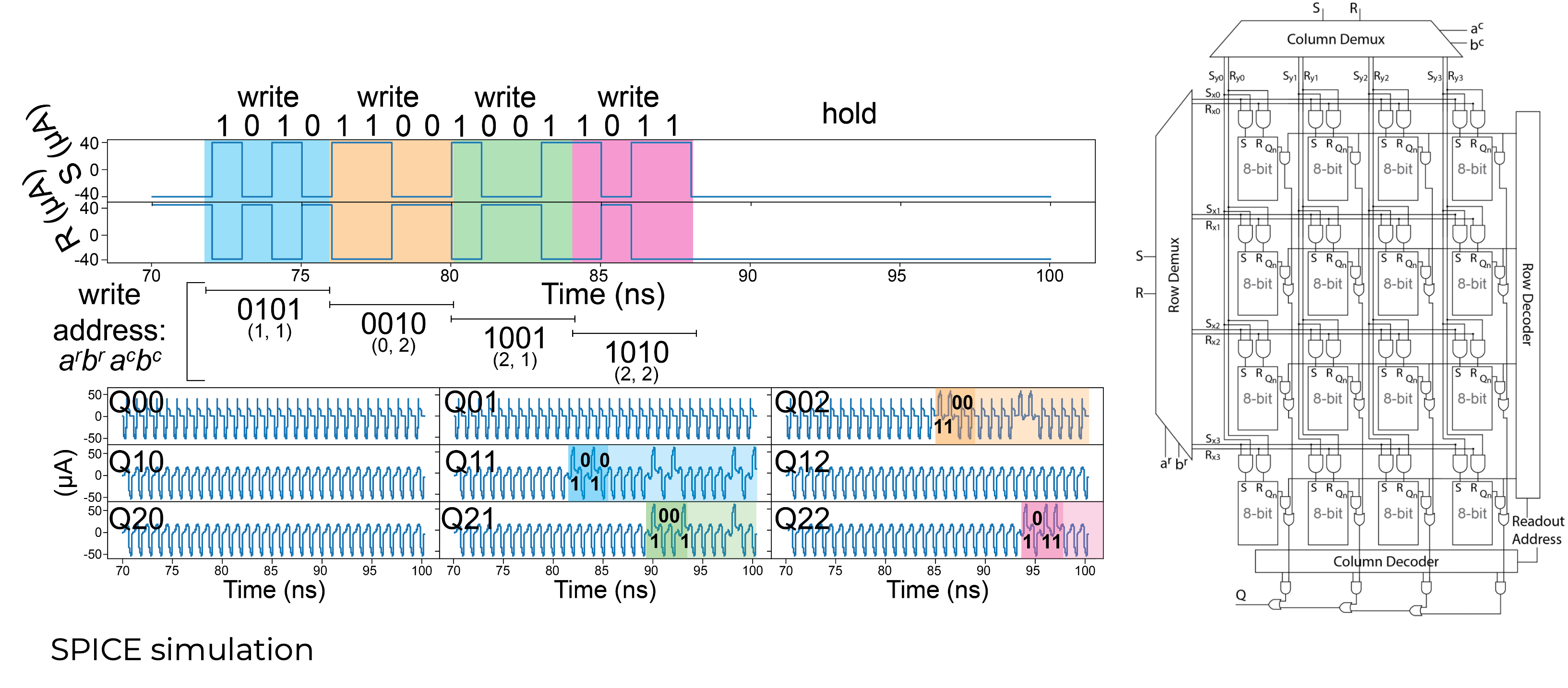
SR-Loop Memory Cell: 3-bit
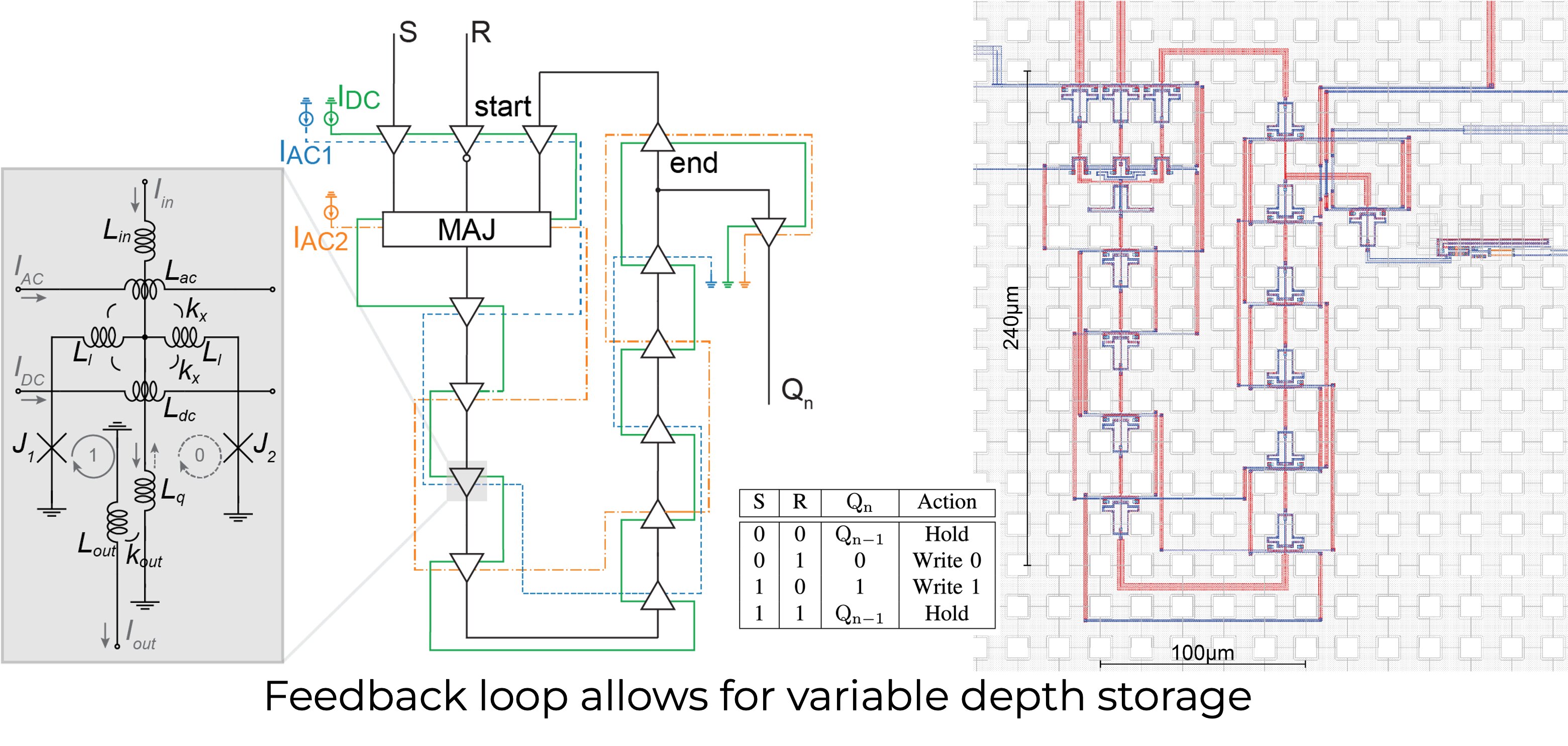
SR-Loop Memory Cell: 3-bit
SR-Loop Memory Cell: 8-bit
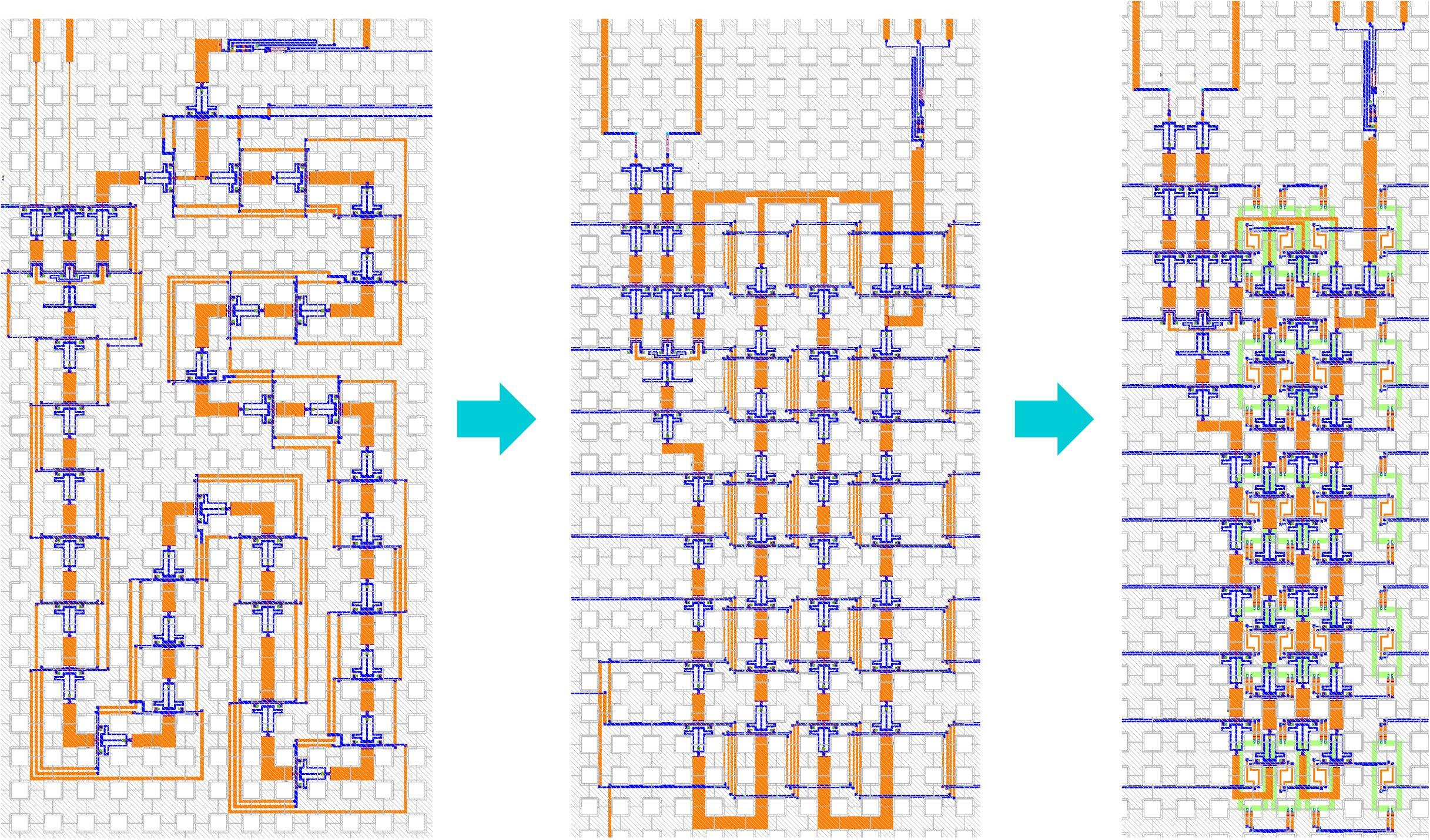
SR-Loop Memory Cell: 8-bit
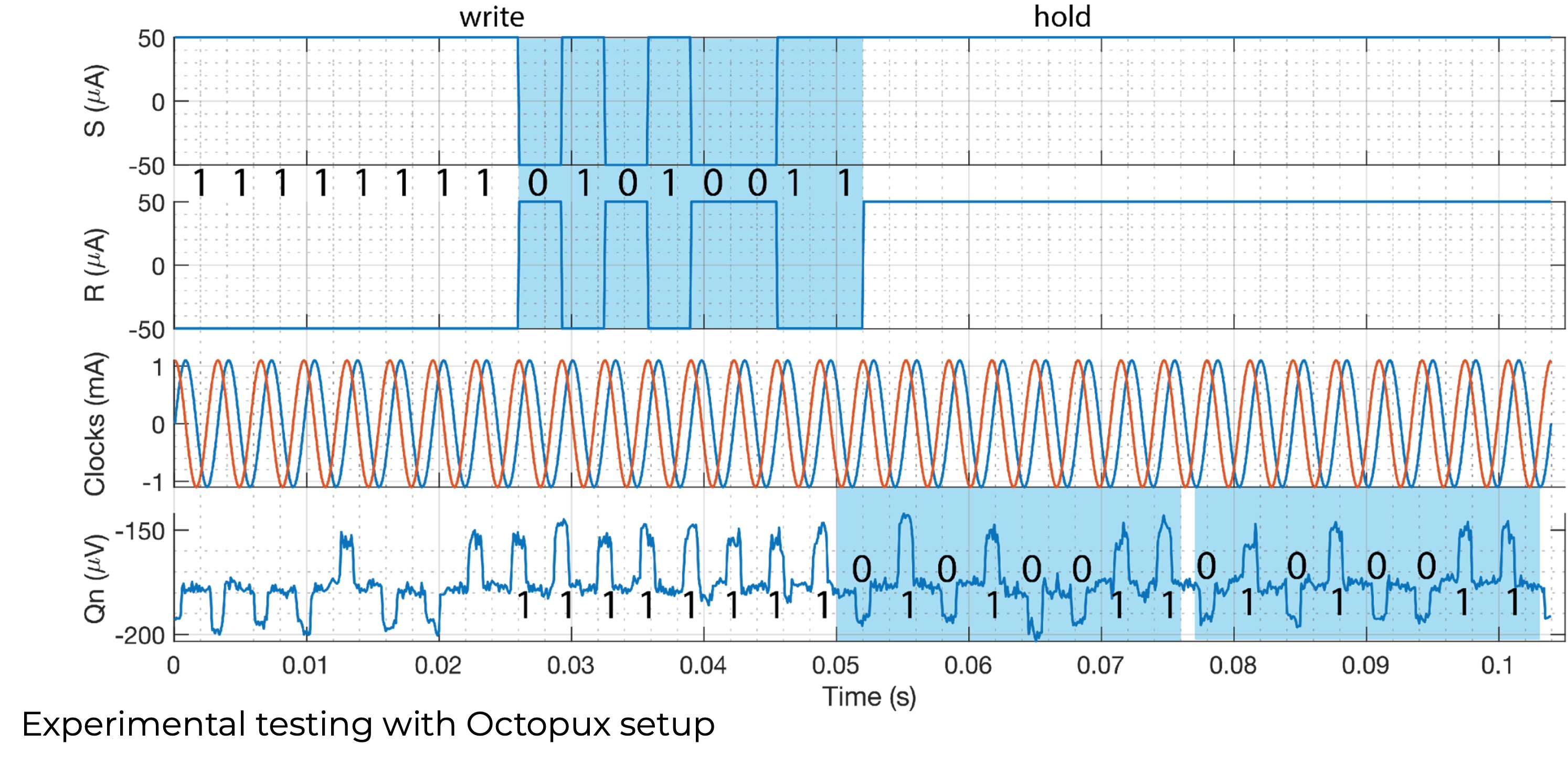
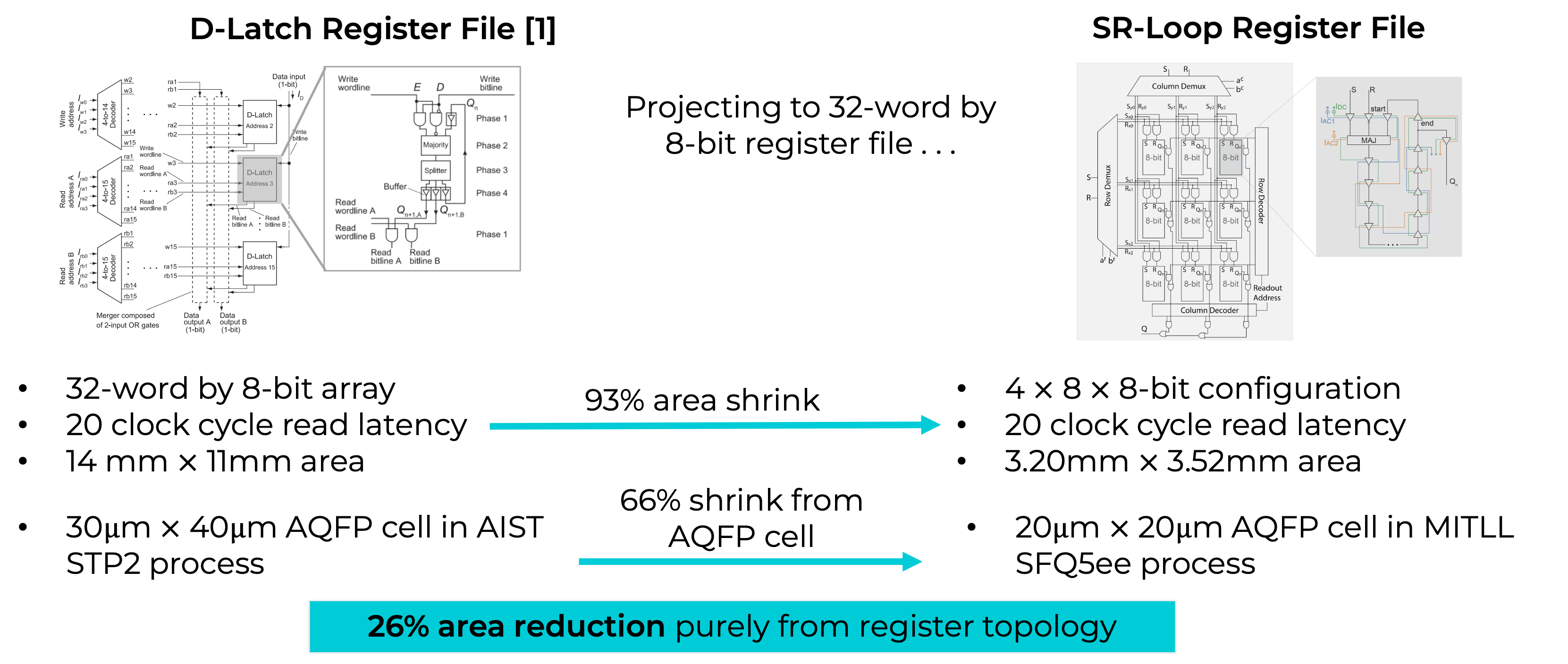
SR-Loop Register File v1
SR-Loop Register File v1
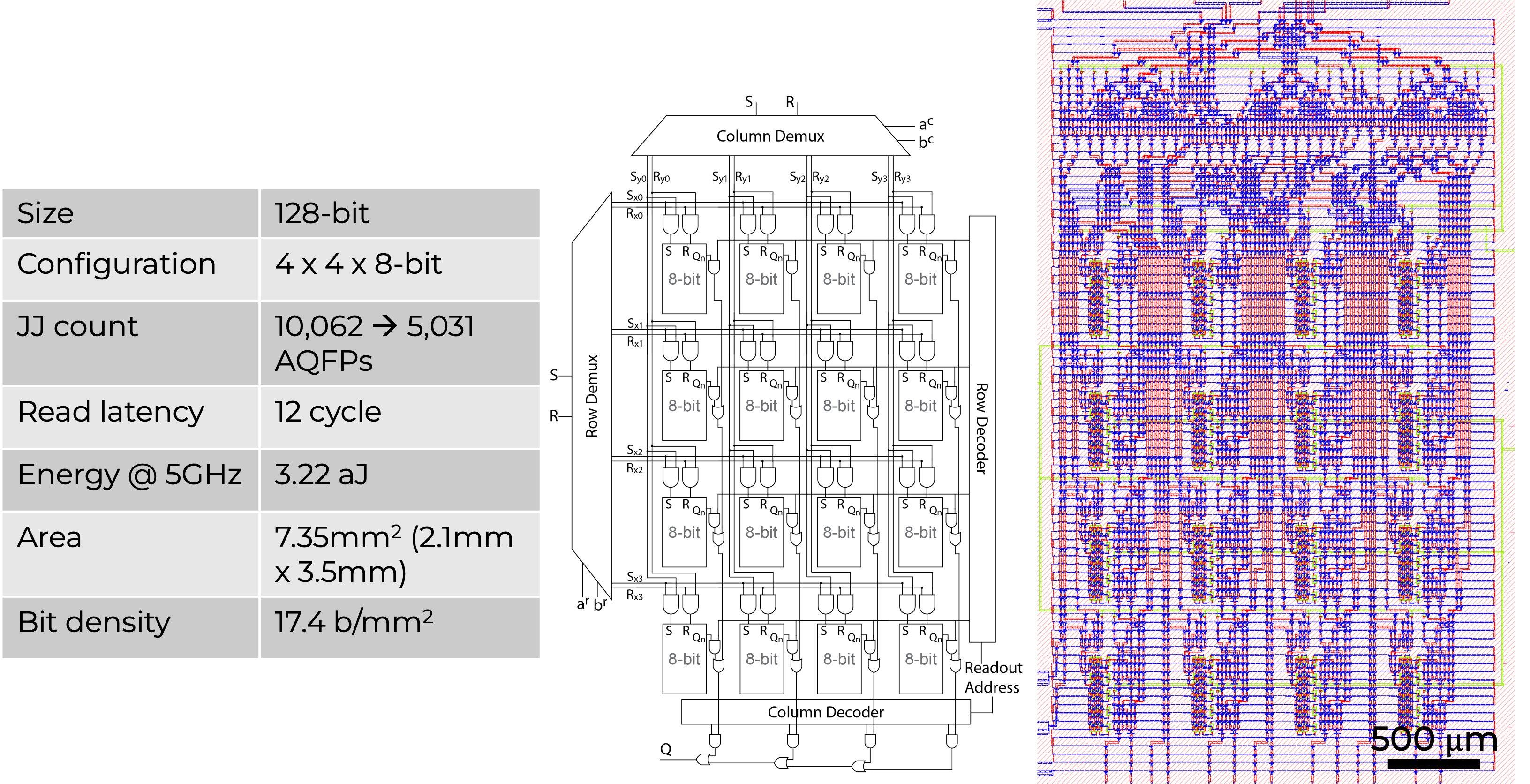
Comparison to existing AQFP RF
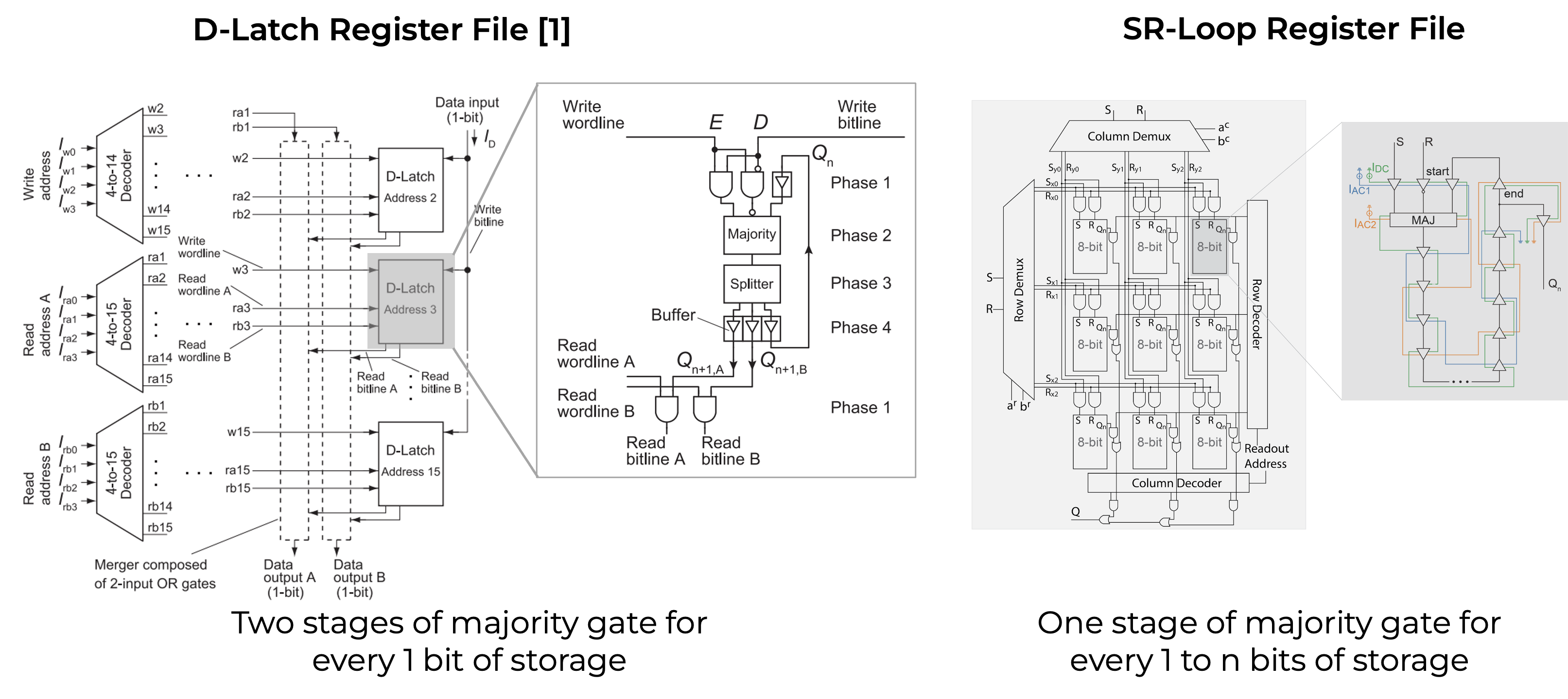
Comparison to existing AQFP RF
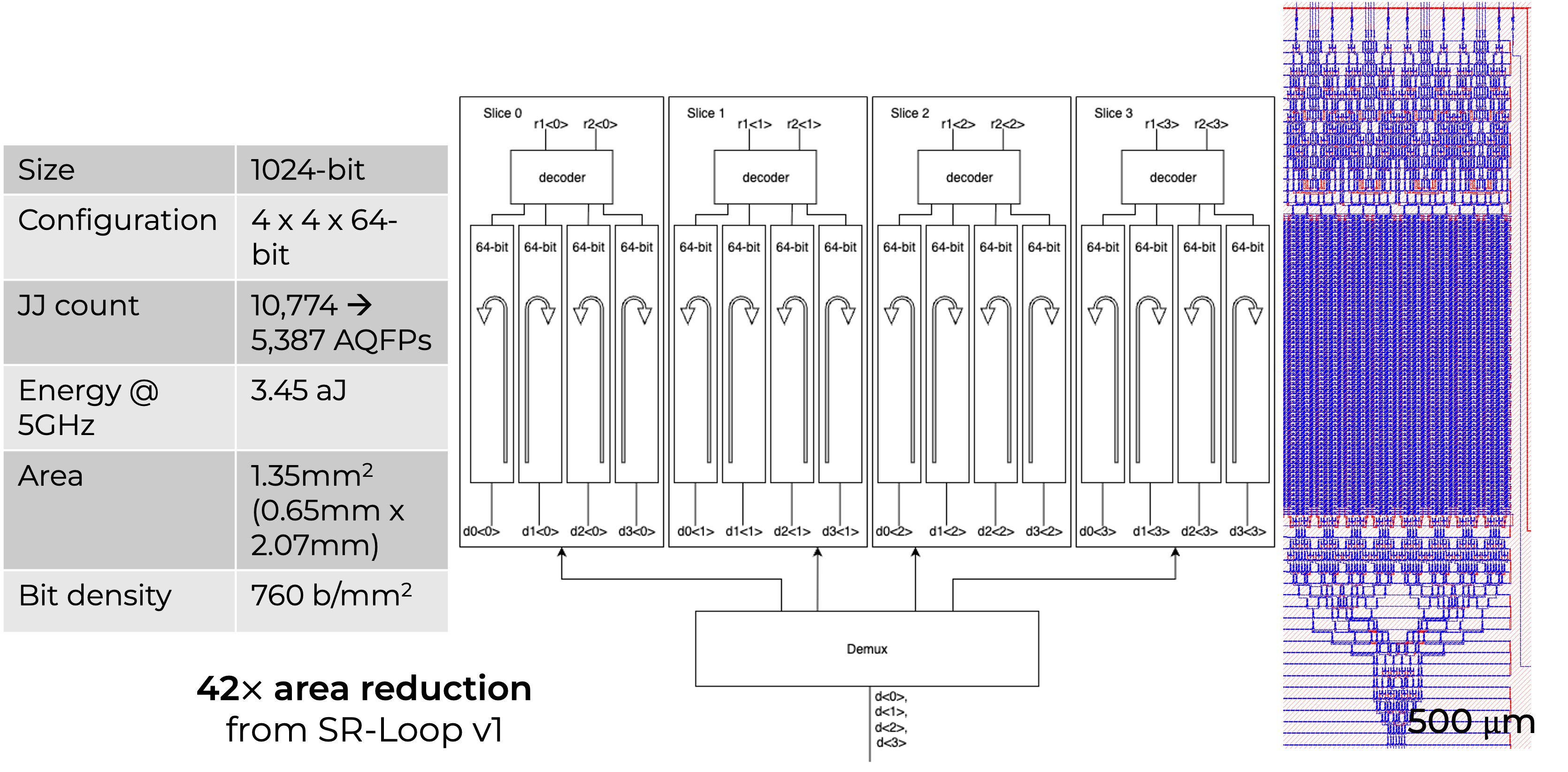
SR-Loop Register File v2
Microarchitecture
How can we get high throughput matrix multiply compute?

AI workloads do matrix-multiplication
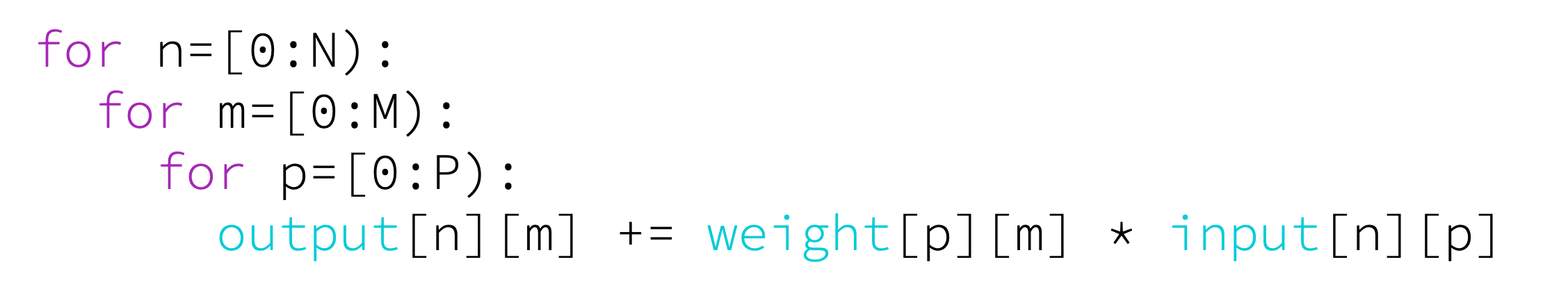

LinCore Processor
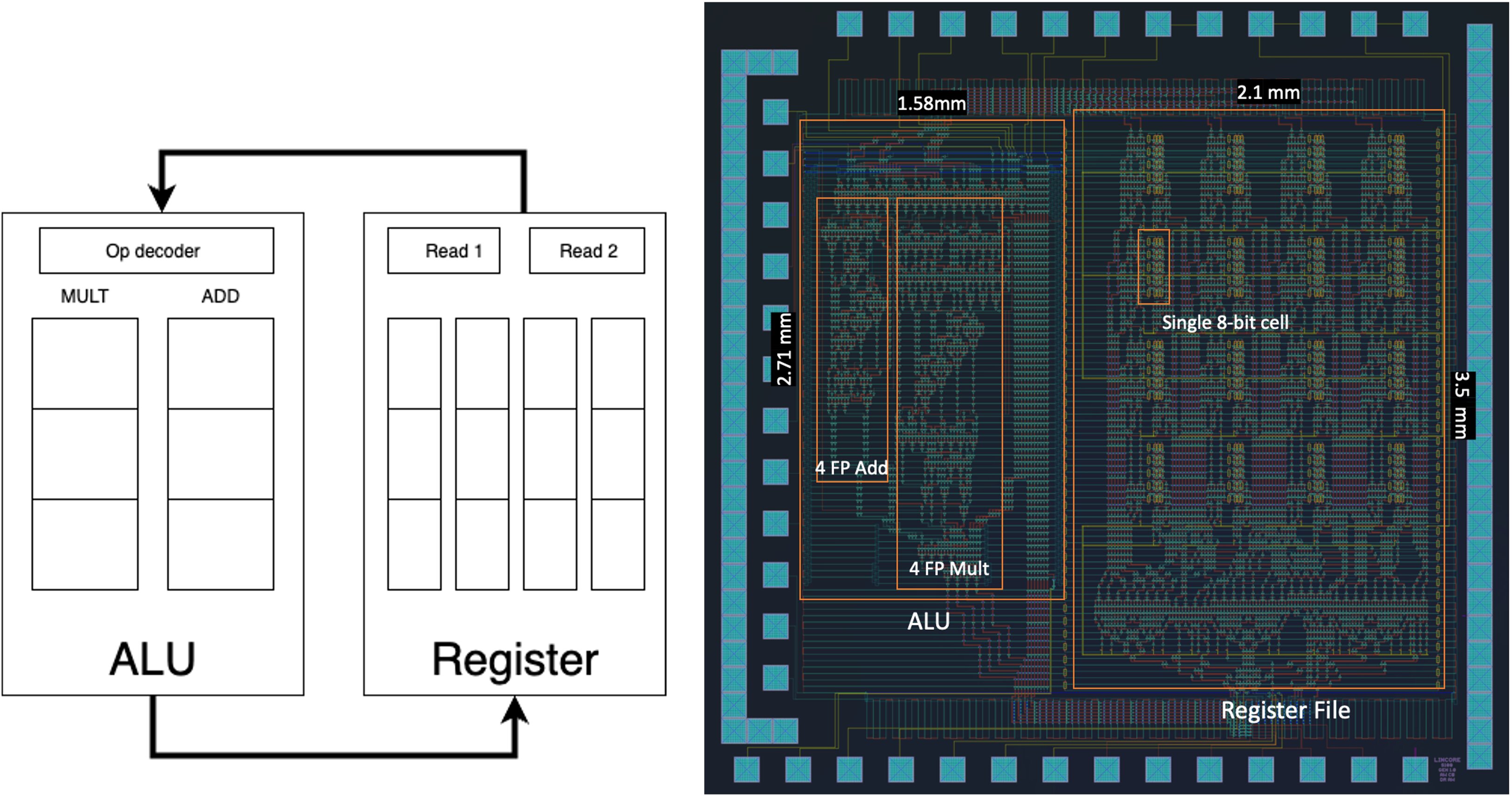
Single MAC on LinCore processor
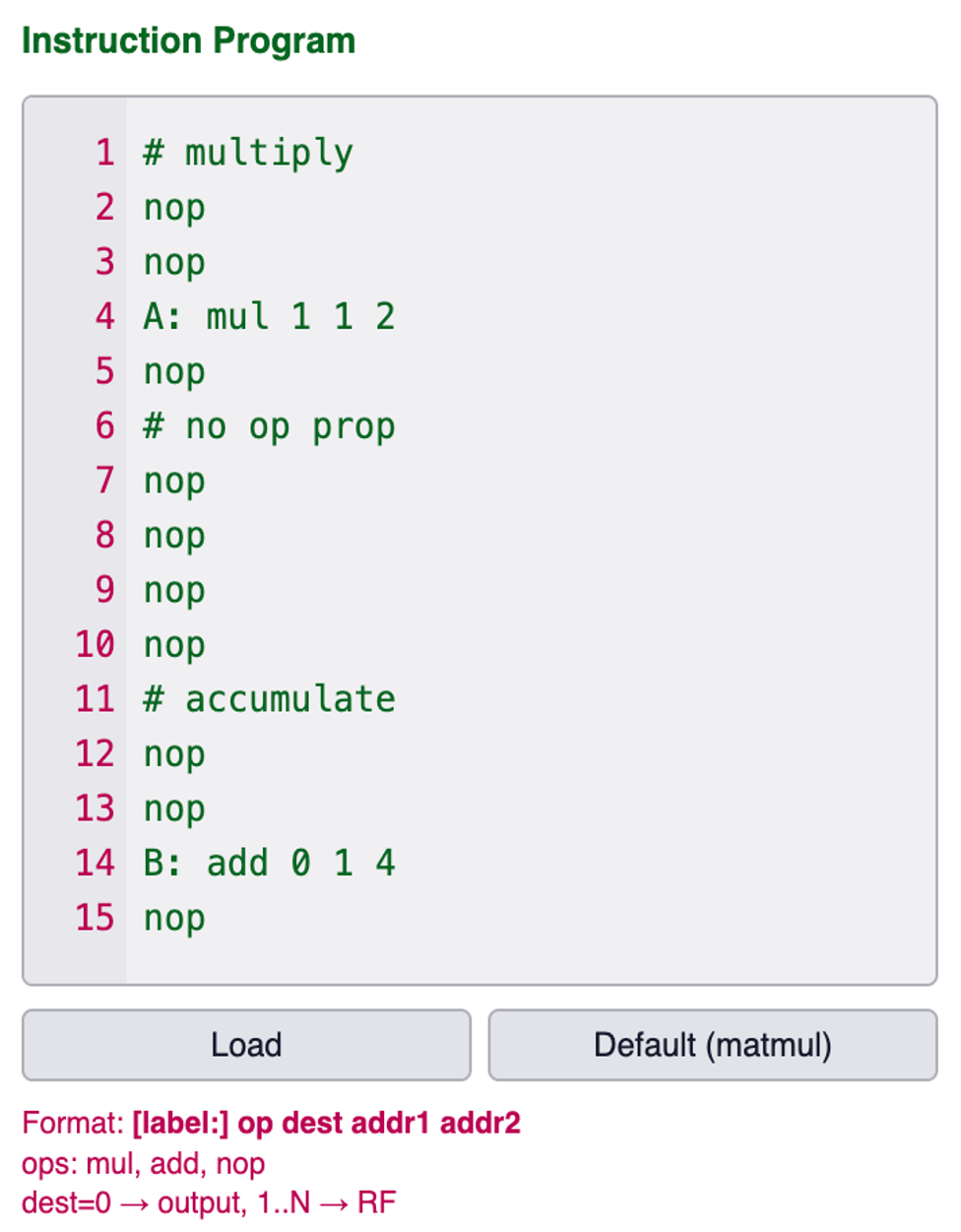
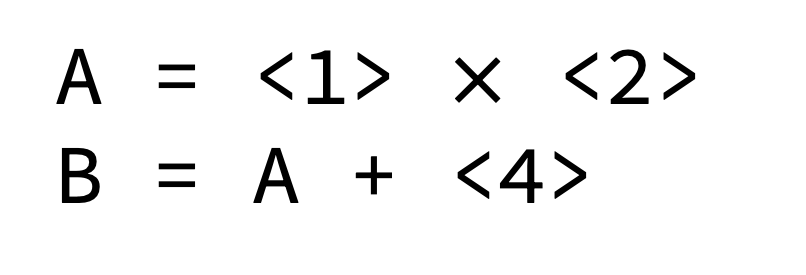
2x2 Matrix Multiplication on LinCore processor
Architecture
Now that we've built the components, how do we piece them together? How much of the 100× device-level advantage is carried to the full system?

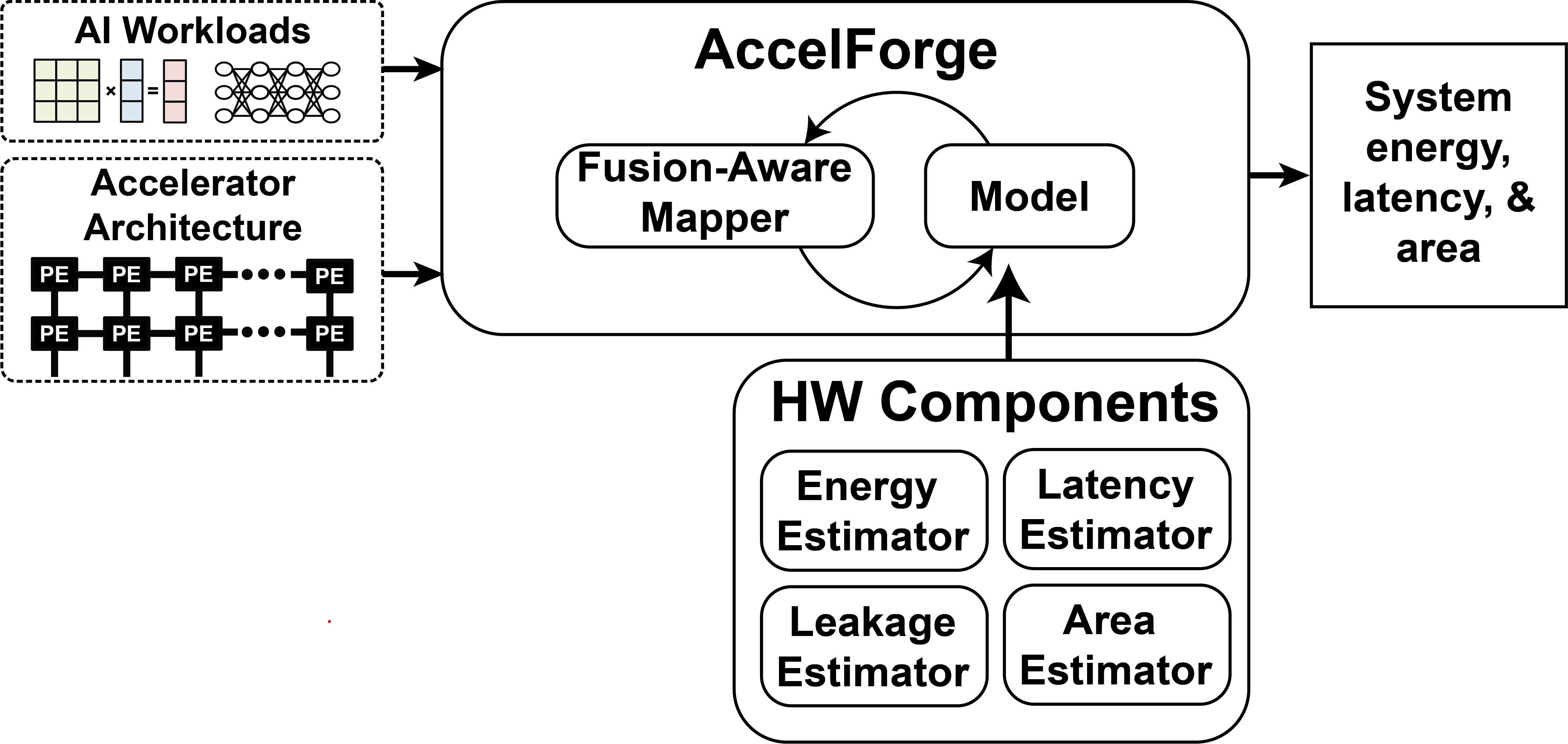
Architecture design-space exploration tool
- Flexible and easily customizable
- Extendable to new technologies or novel circuit topologies
- Full-stack model (from devices to application workloads)
- Fast execution for rapid design space exploration
- Accurate comparison to existing state of the art CMOS
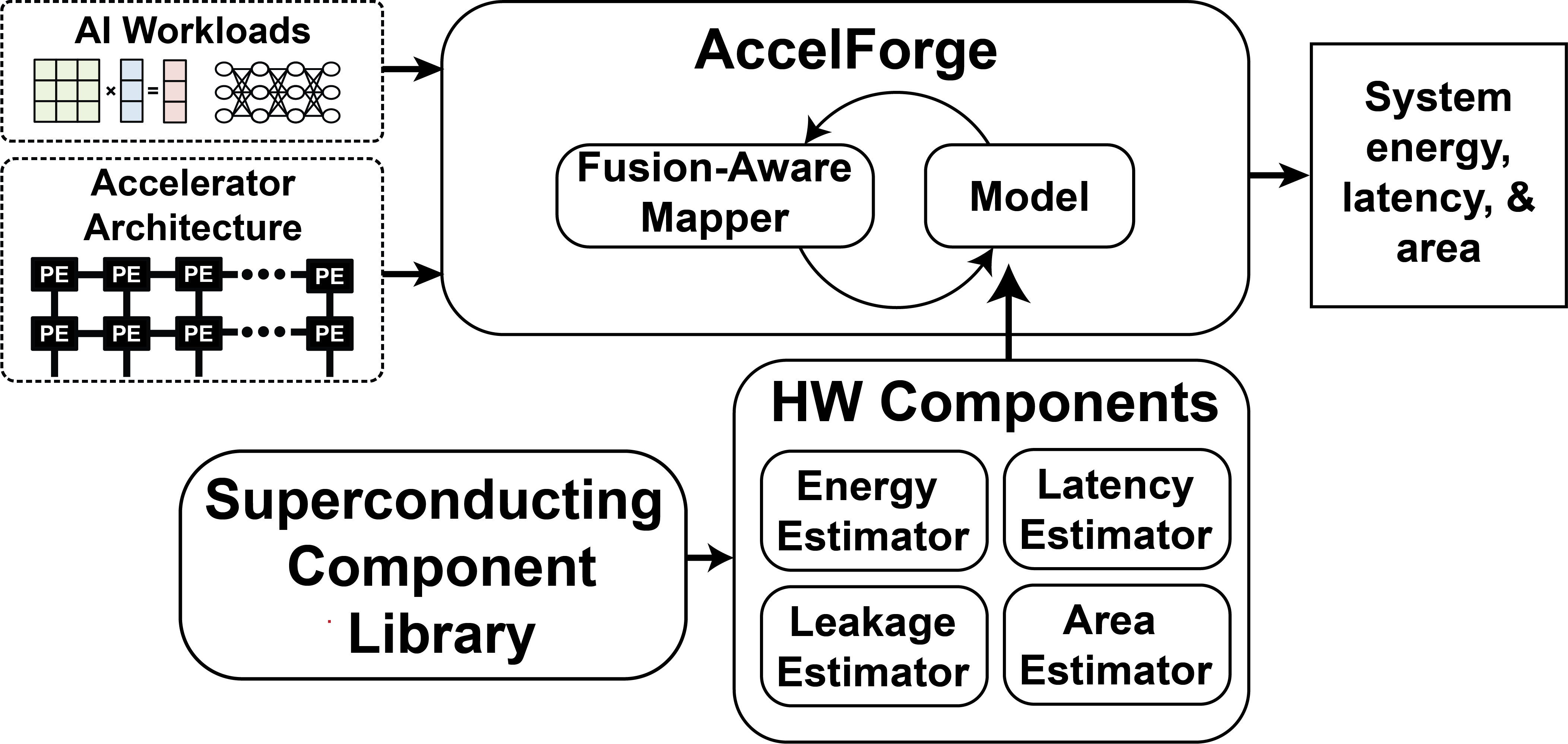

AI accelerator basics
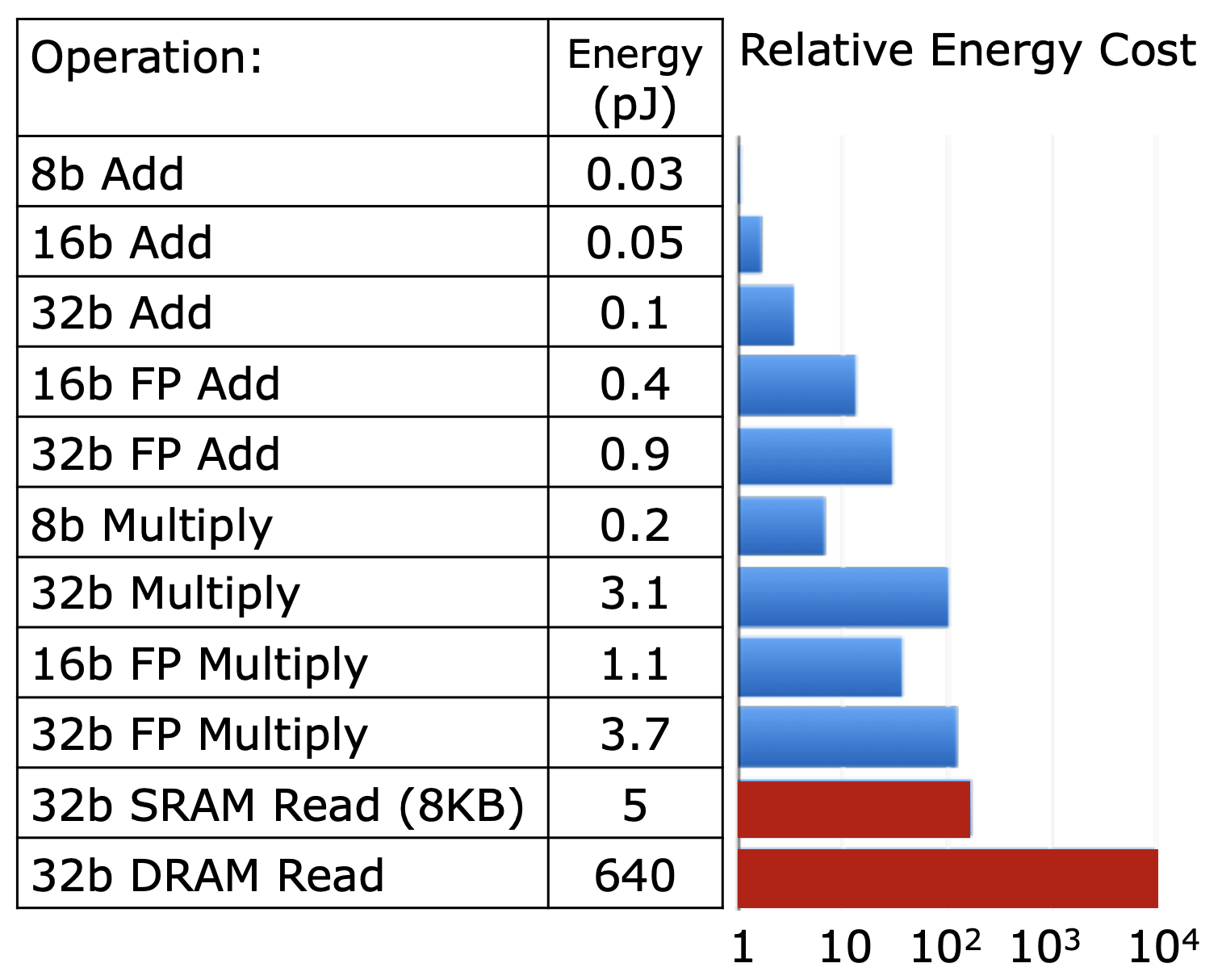
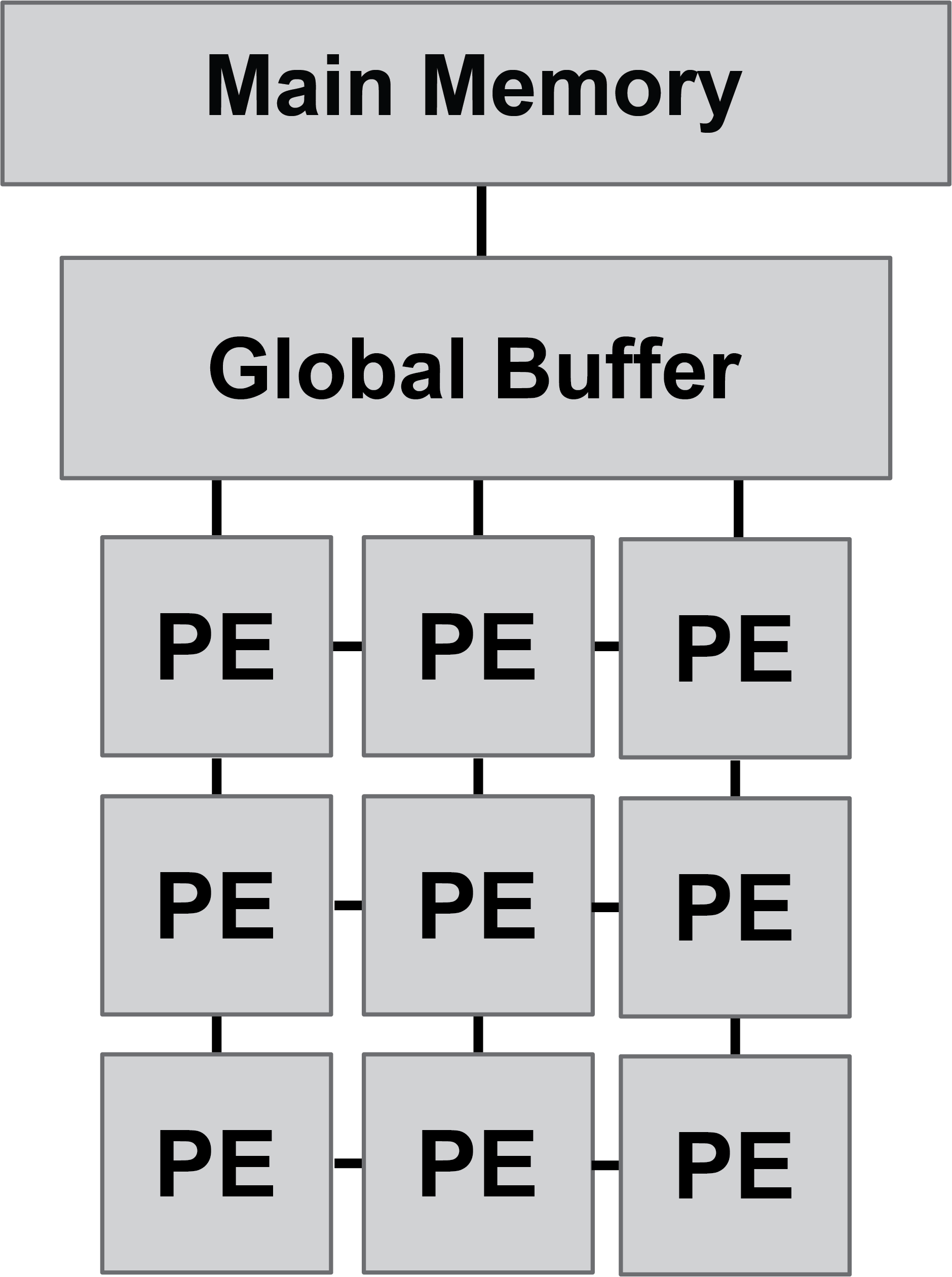
AI accelerator basics
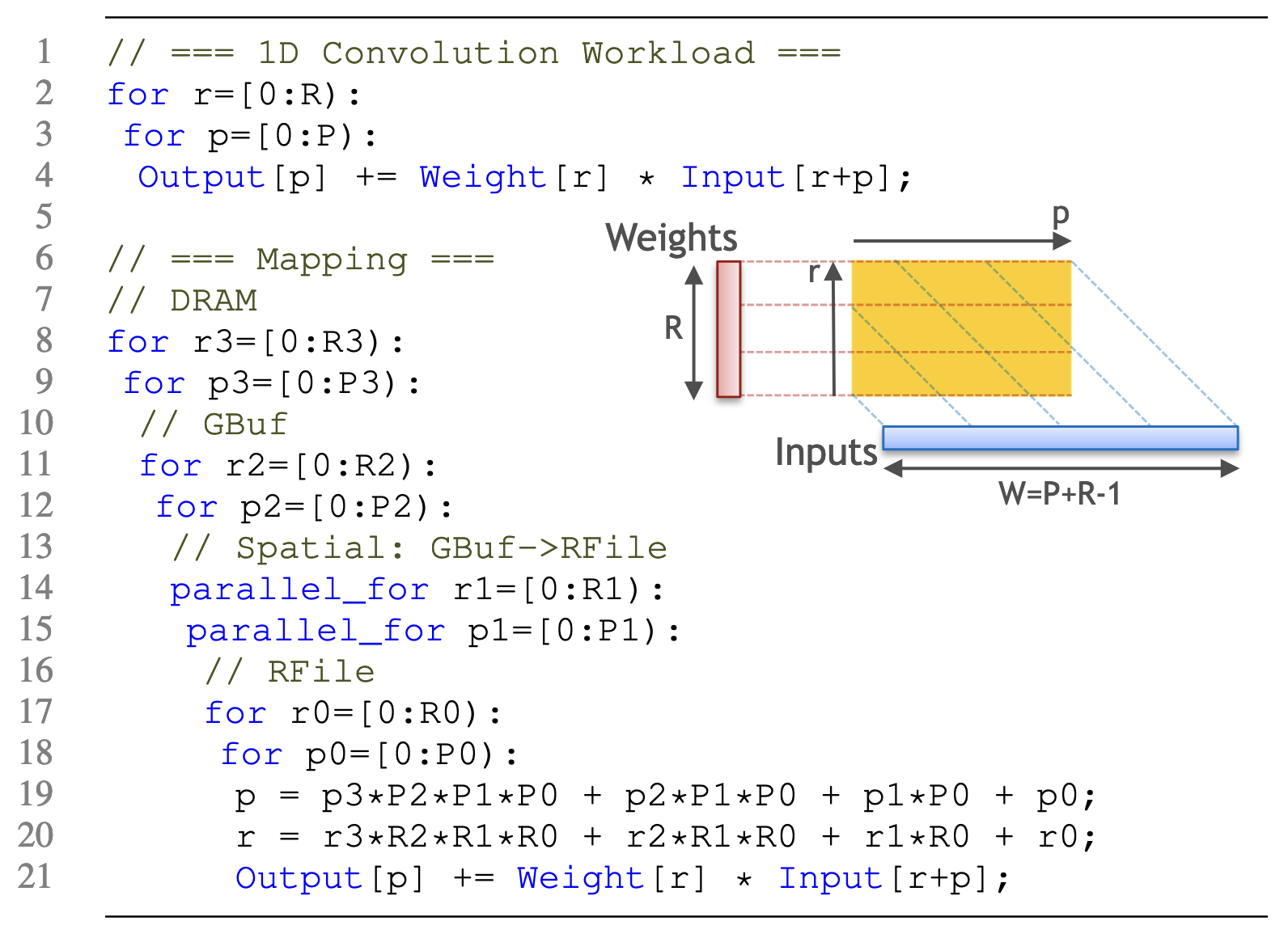
Similar throughput mappings can vary nearly 20× in energy efficiency
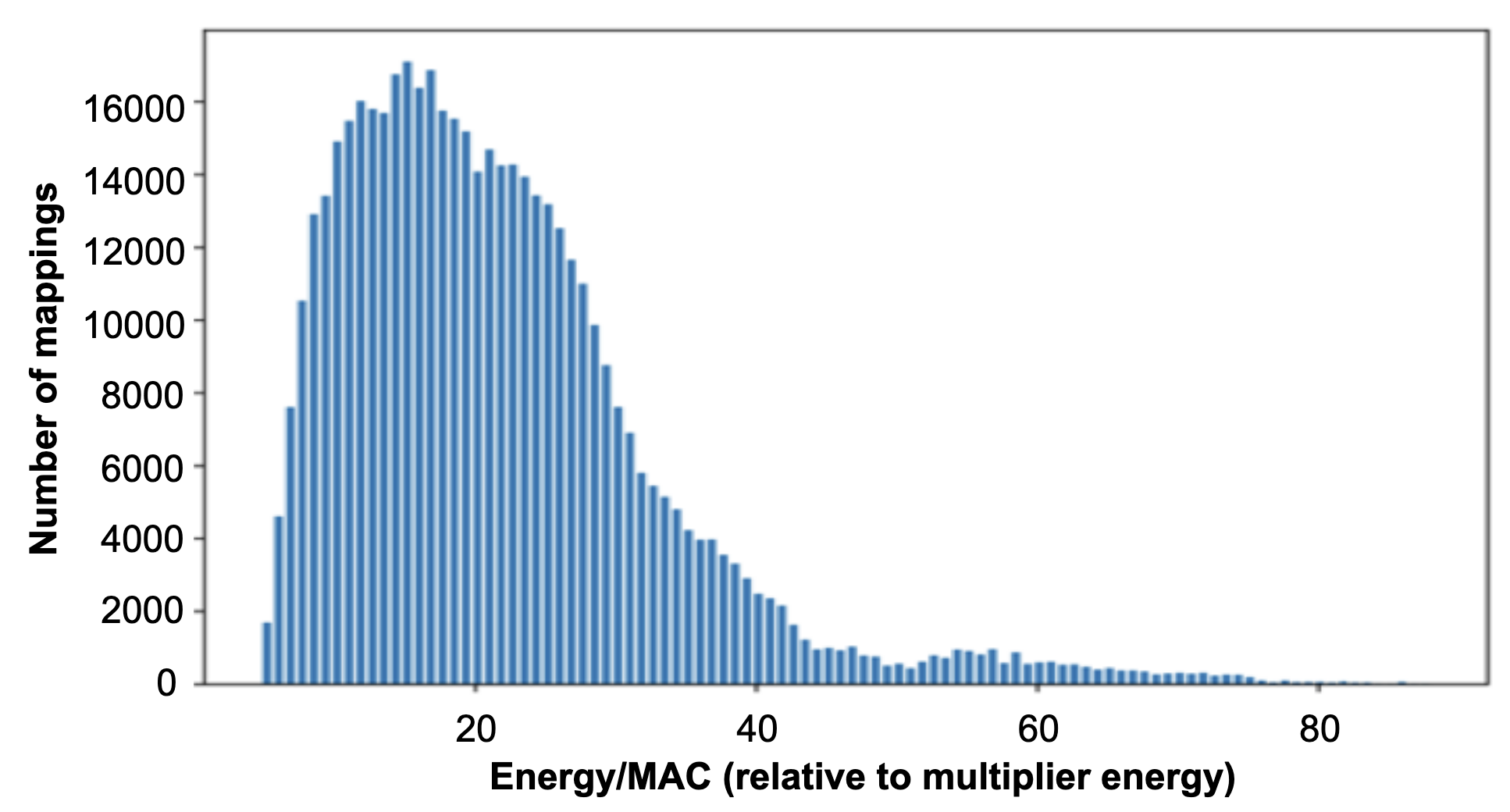
VGG-conv3-2 workload on a 1024-MAC NVDLA-like architecture

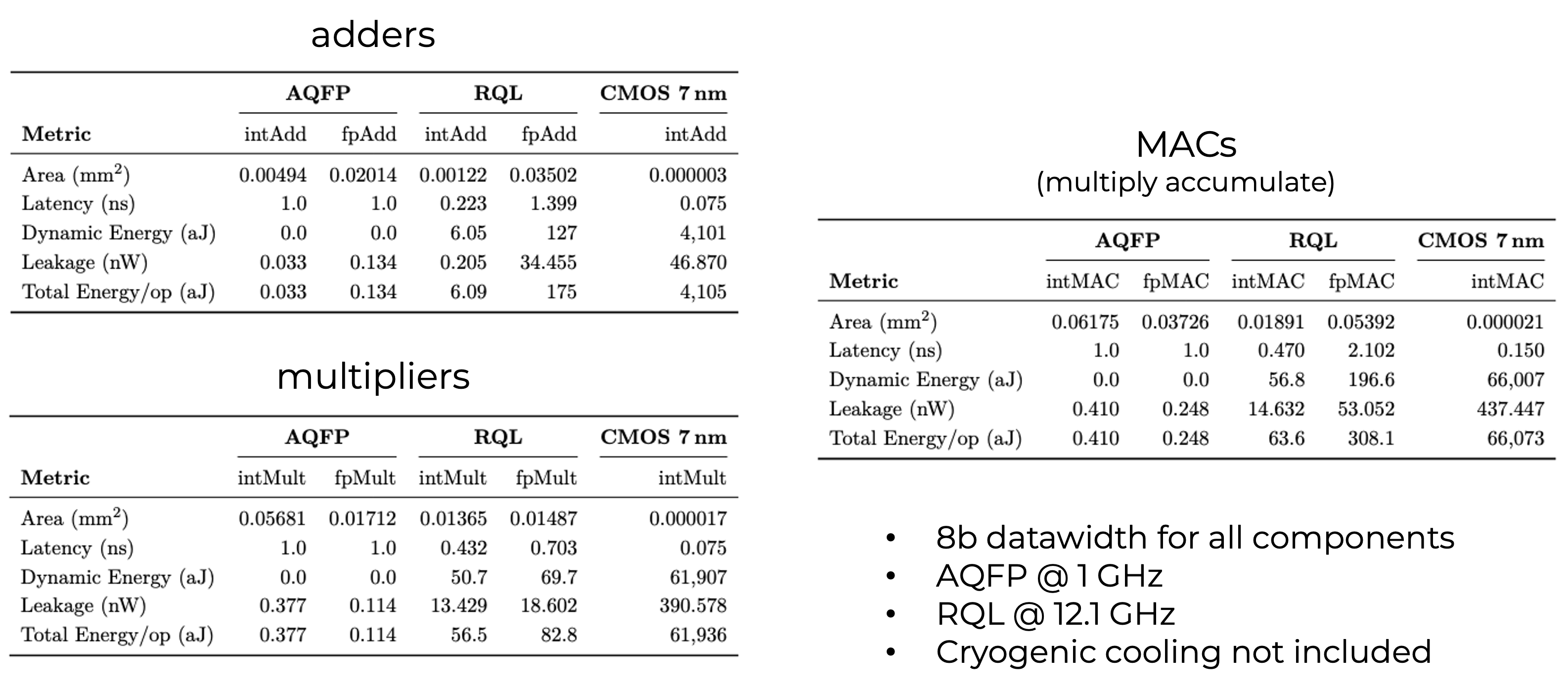
Superconducting models: compute
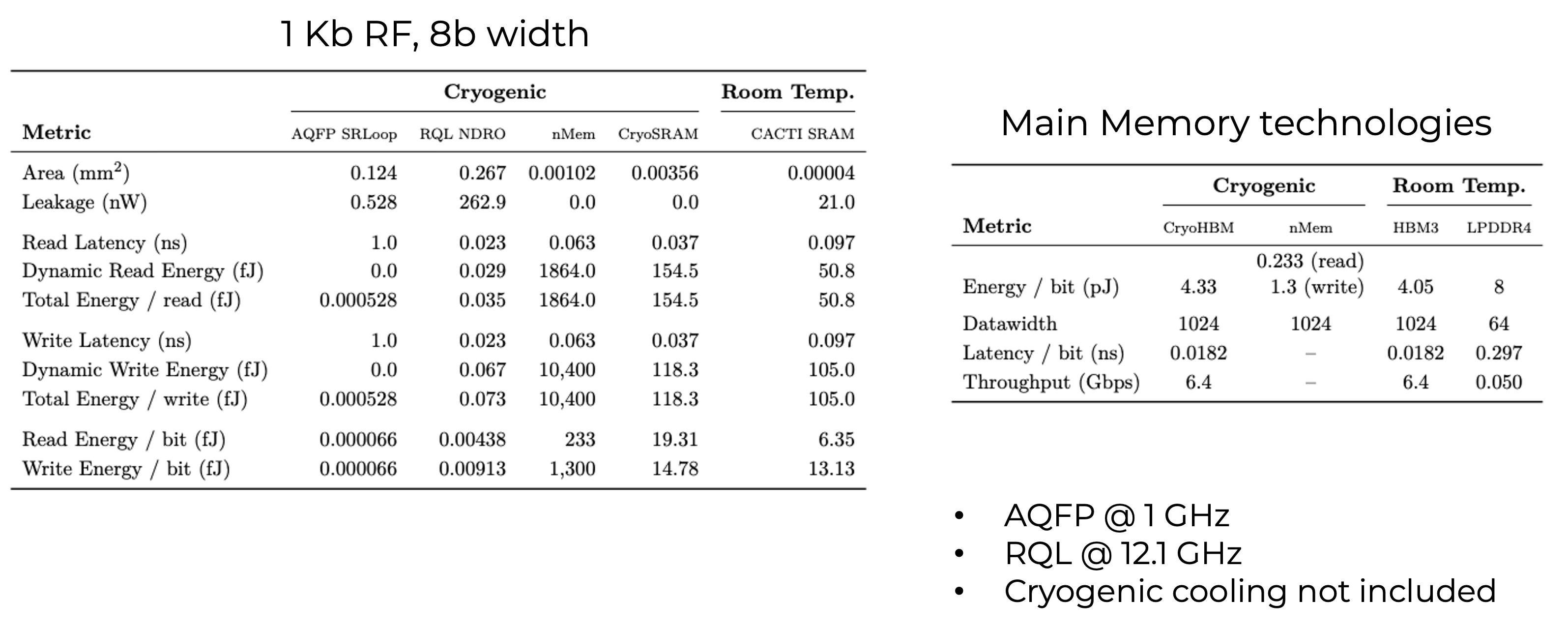
Superconducting models: memory
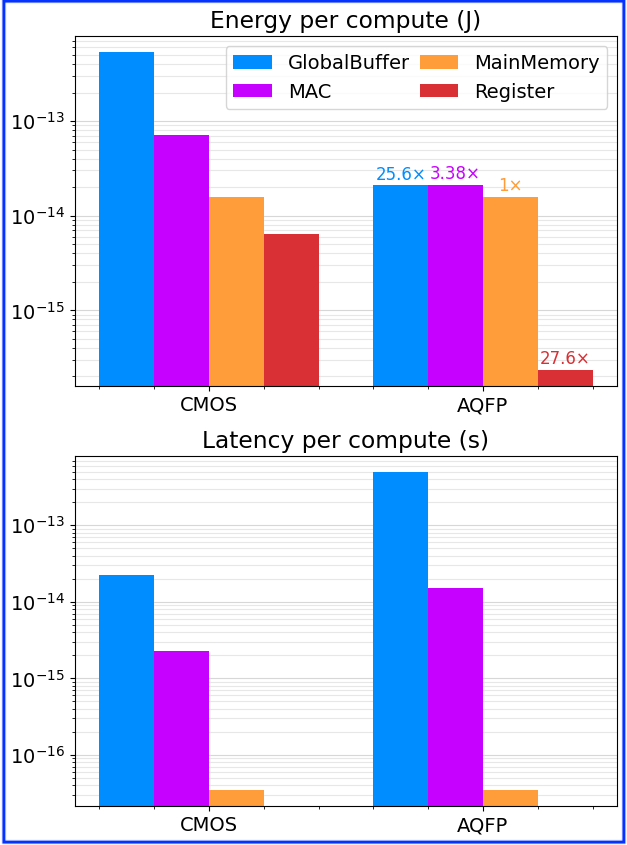
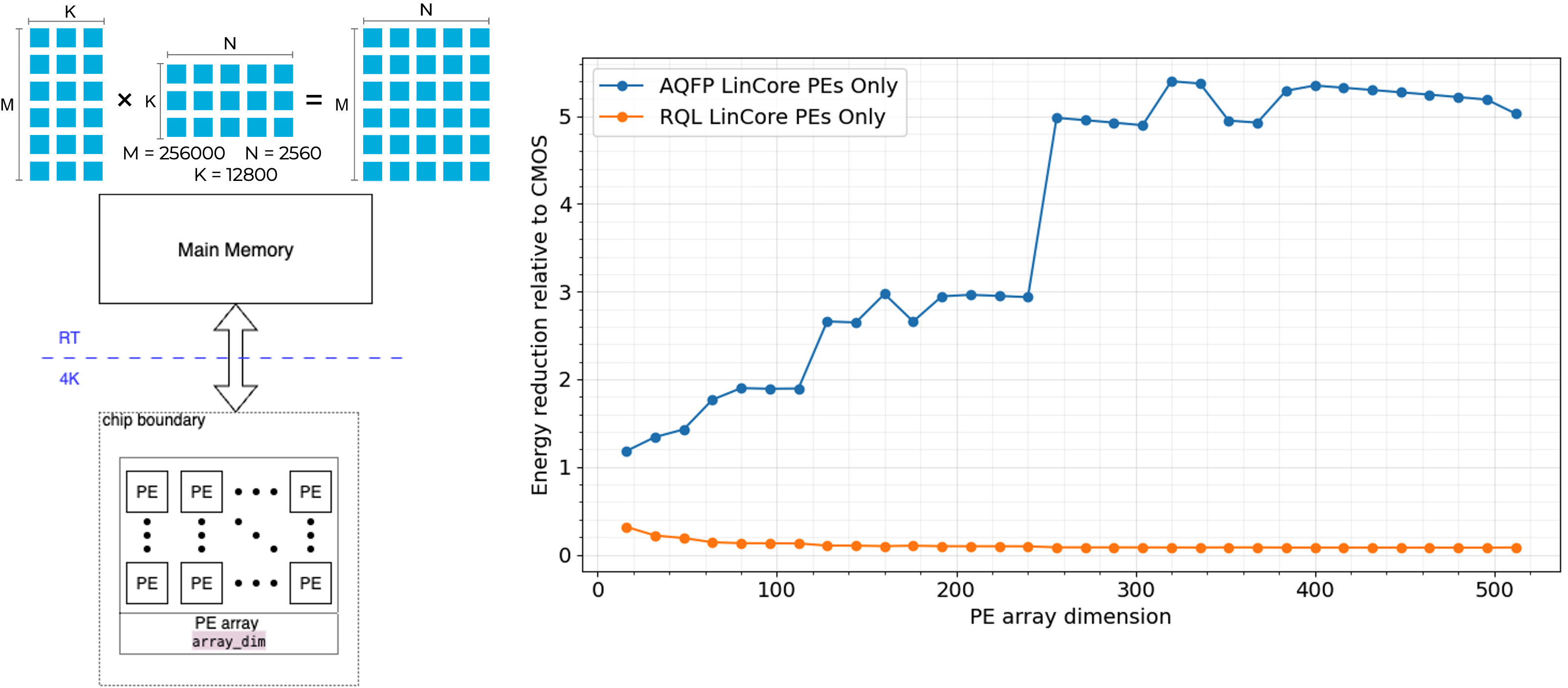
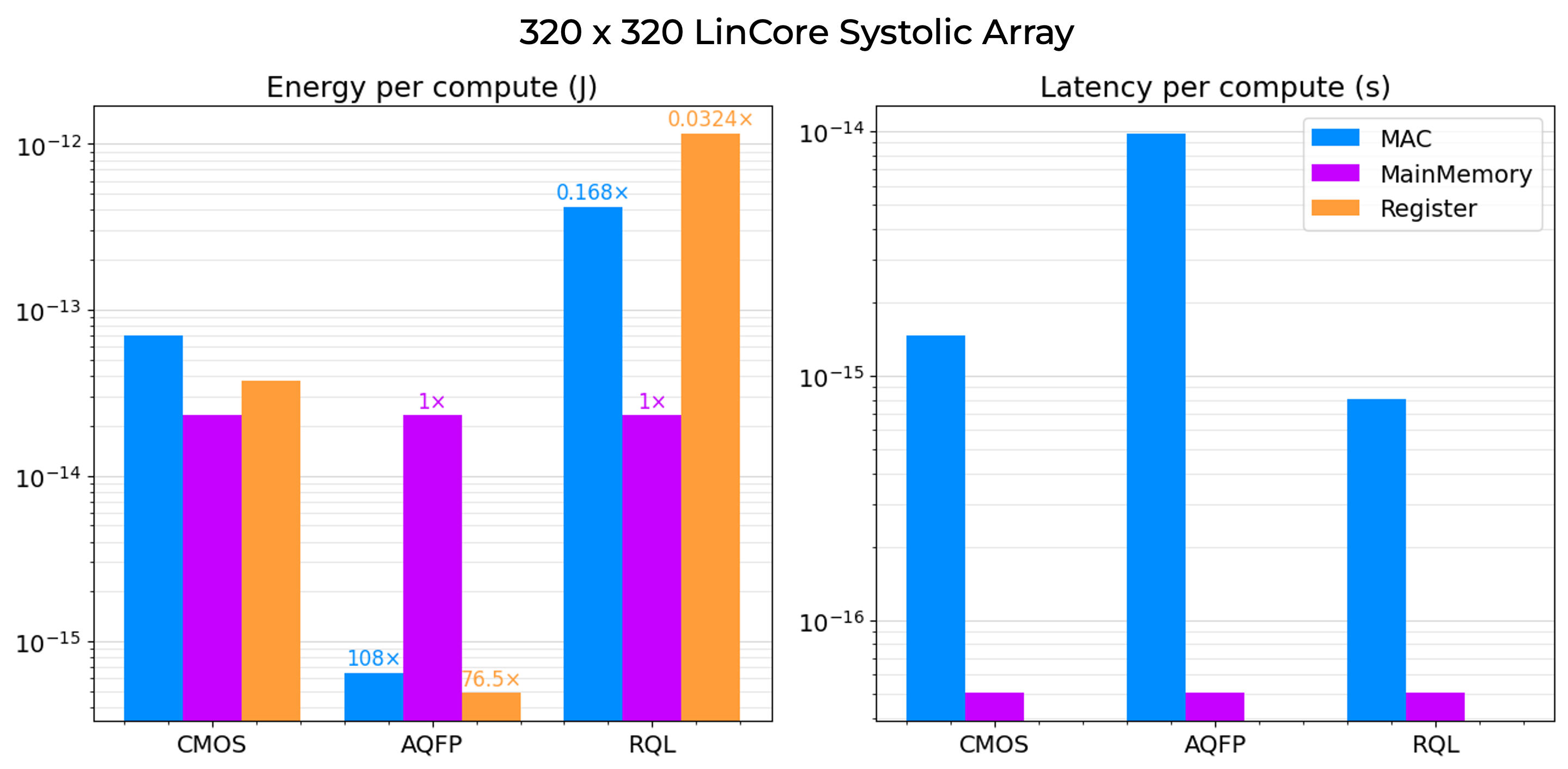
LinCore Systolic Array: 5× energy reduction relative to identical CMOS architecture
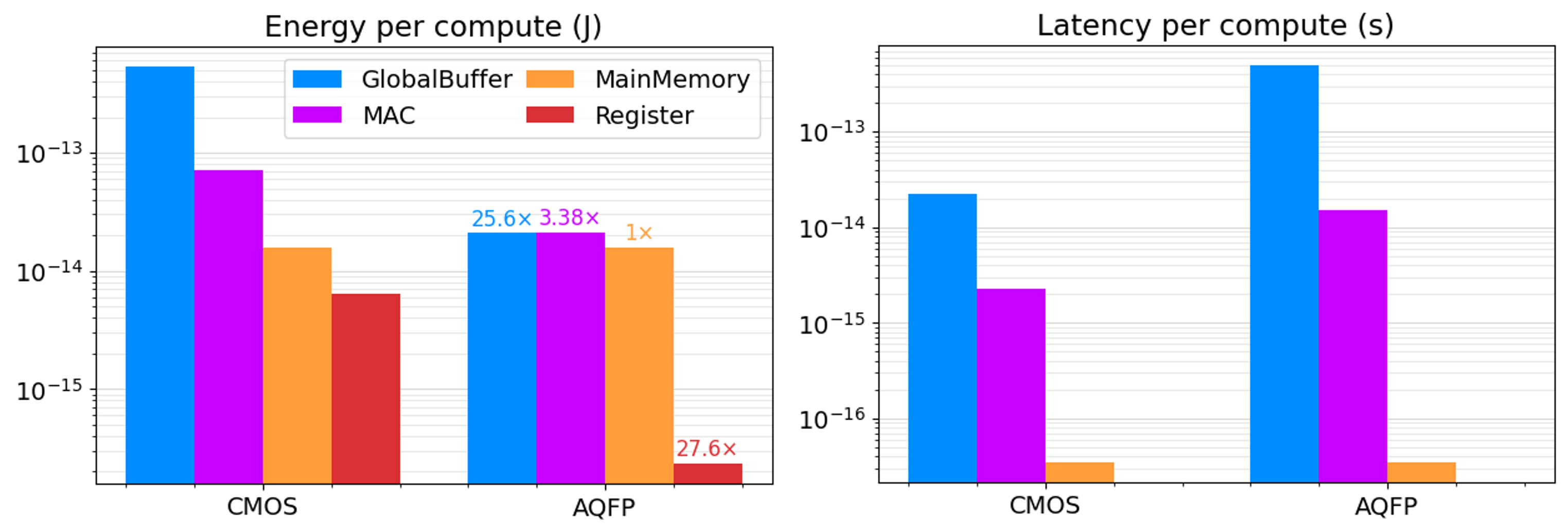
Main memory access dominates energy cost
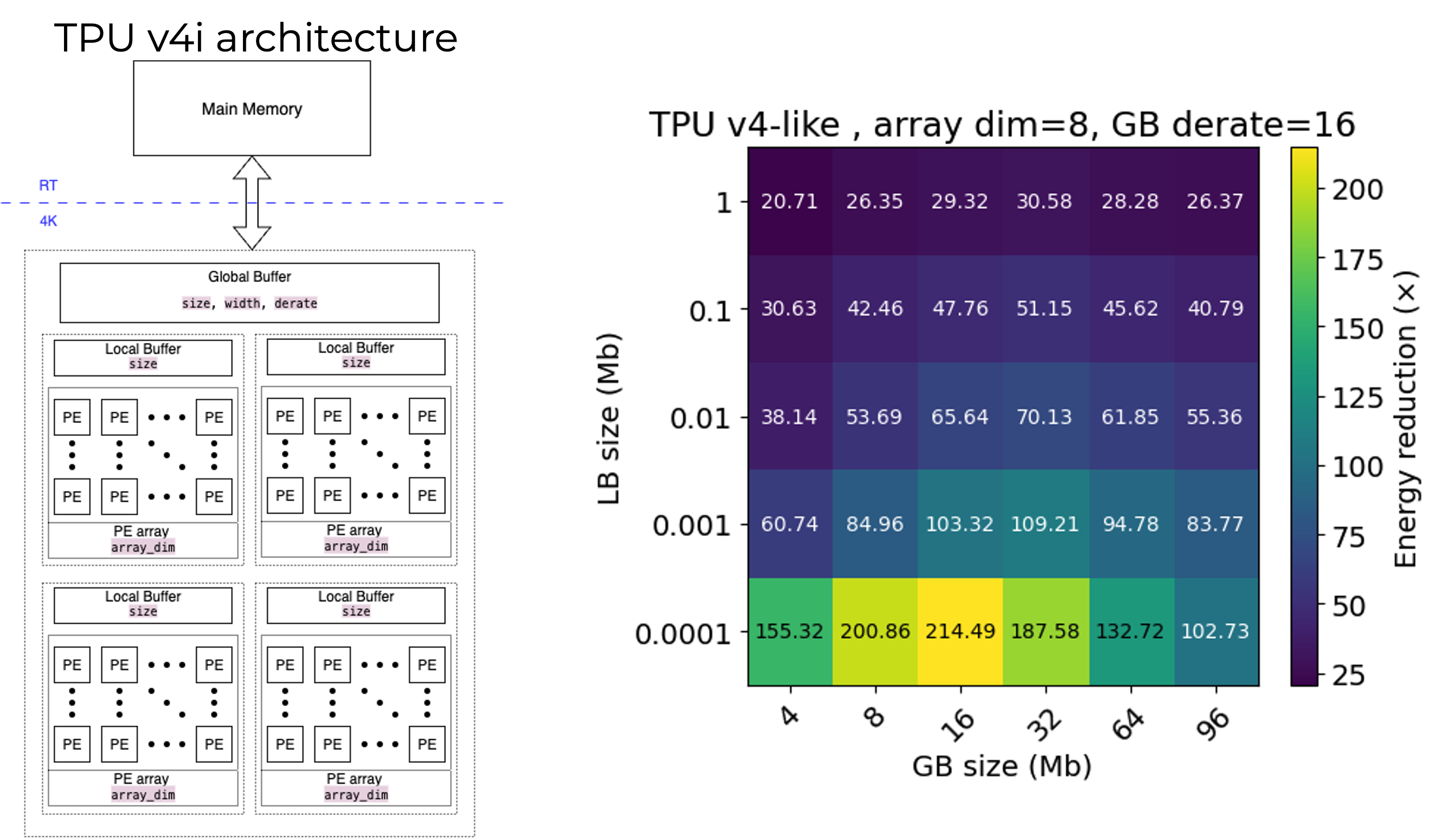
AQFP SR Loop Global Buffer Model
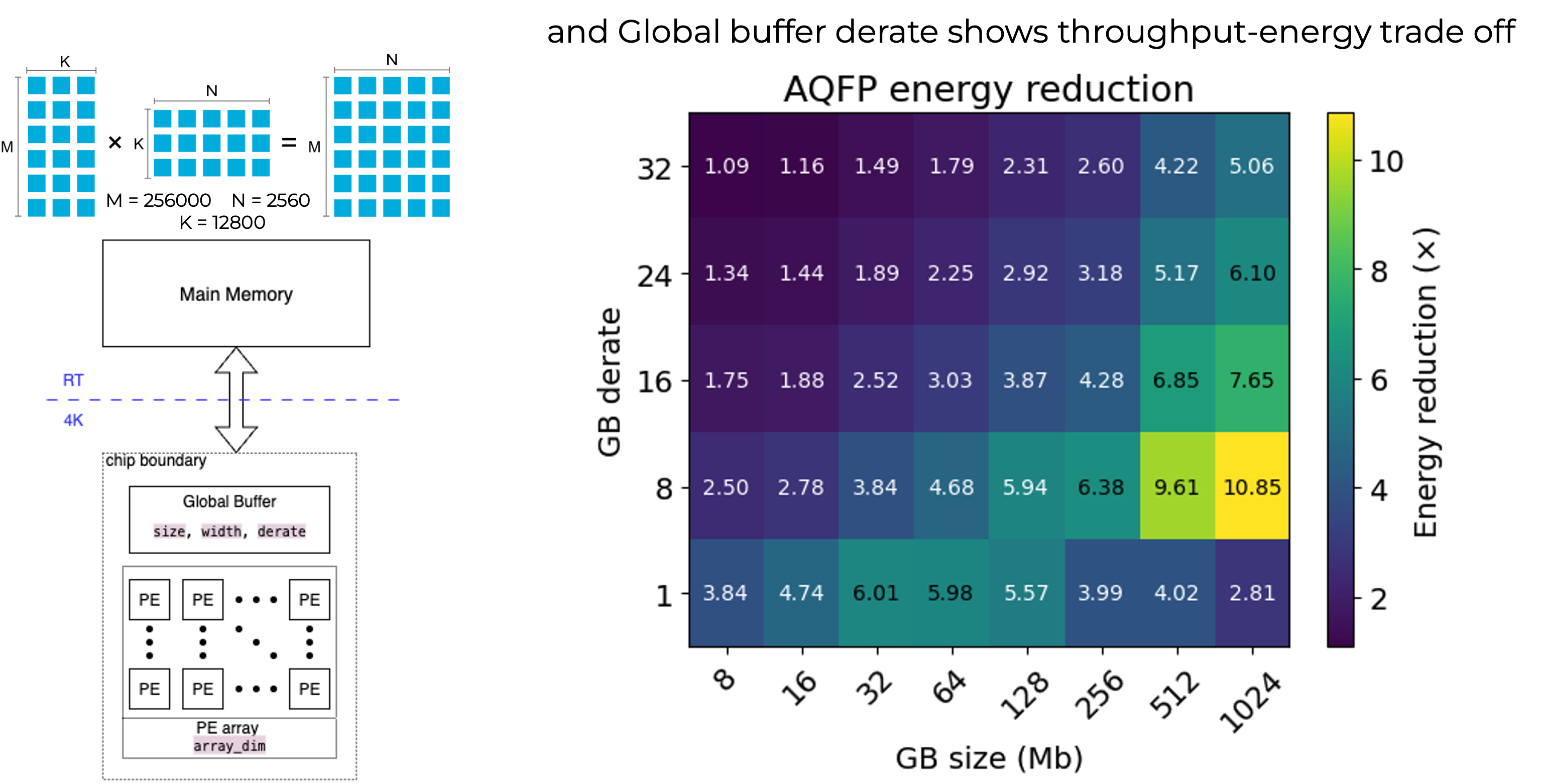
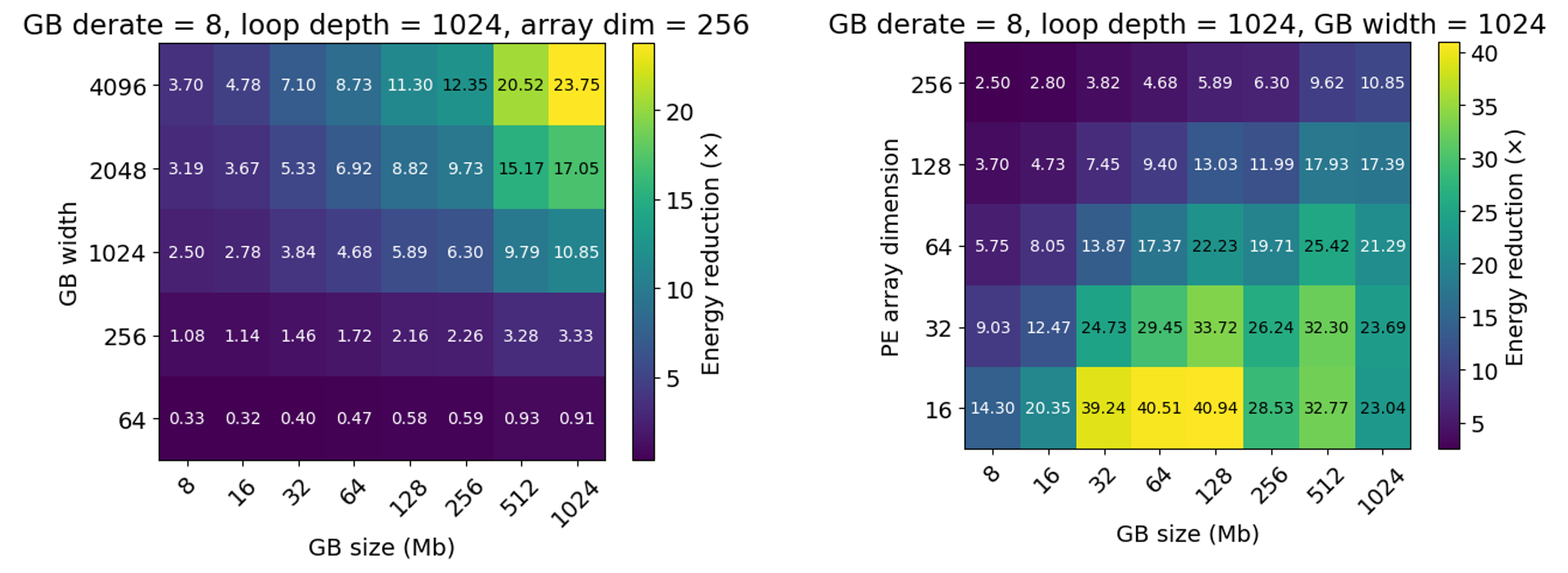
Better energy reduction with larger global buffer
MAC no longer provides 100× energy reduction because Global Buffer latency dominates
Balancing global buffer bandwidth with PE array computer bandwidth results in better energy reduction
Memory hierarchy fanout improves energy efficiency
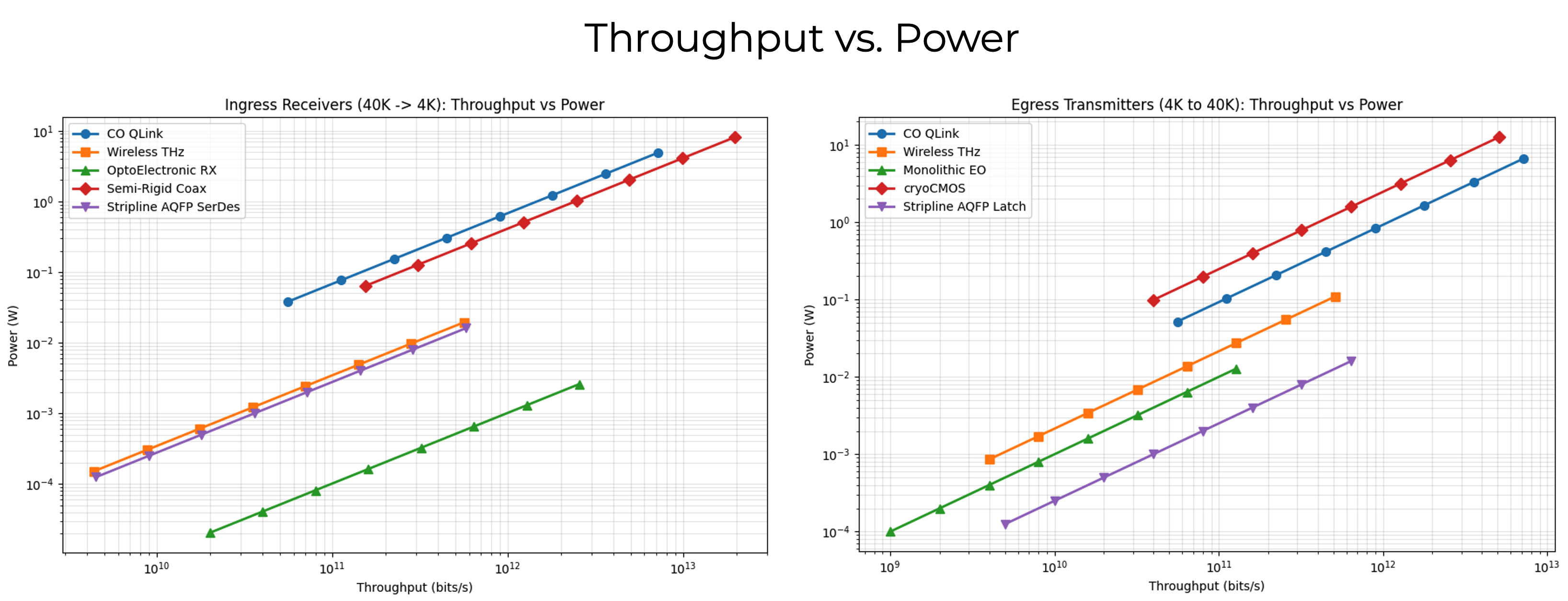
Main memory to 4 K interconnect trade offs
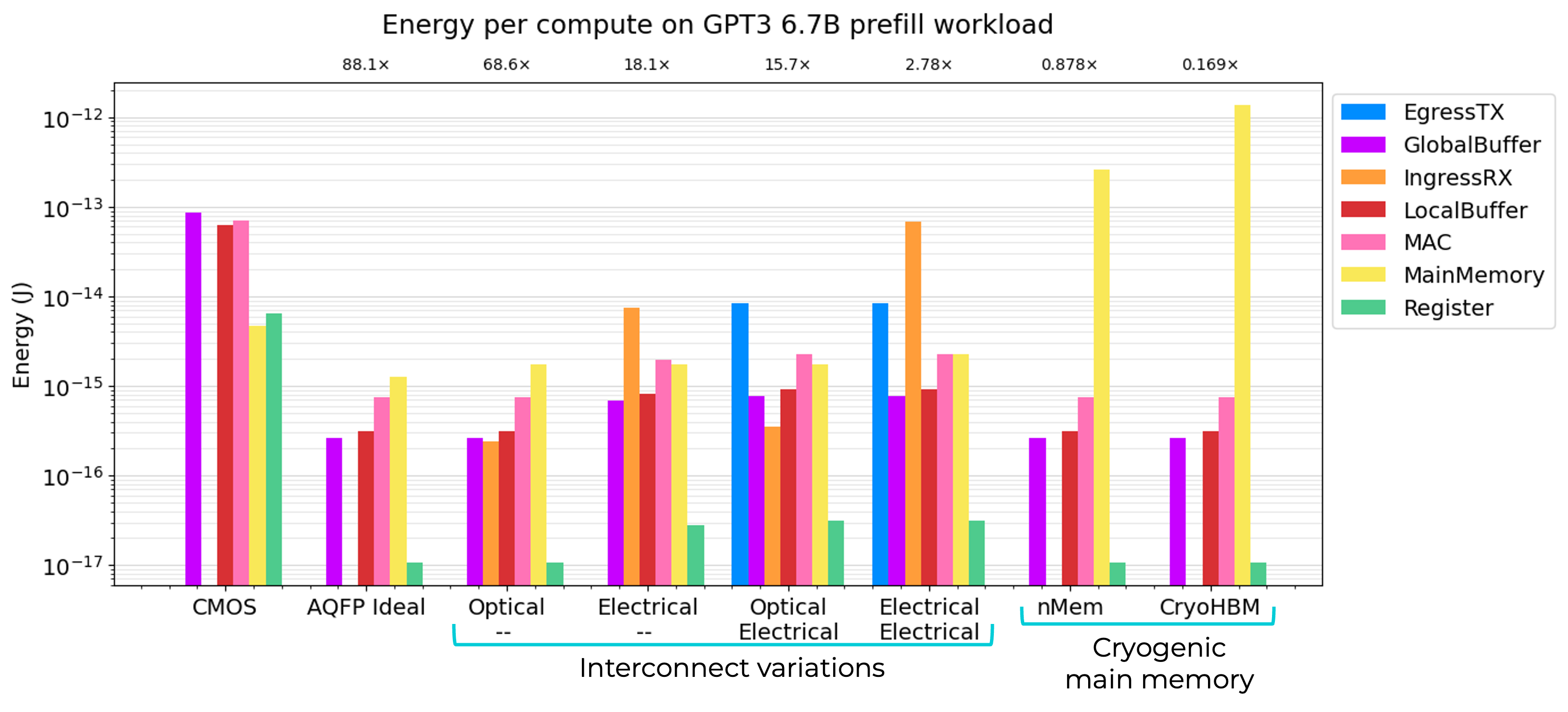
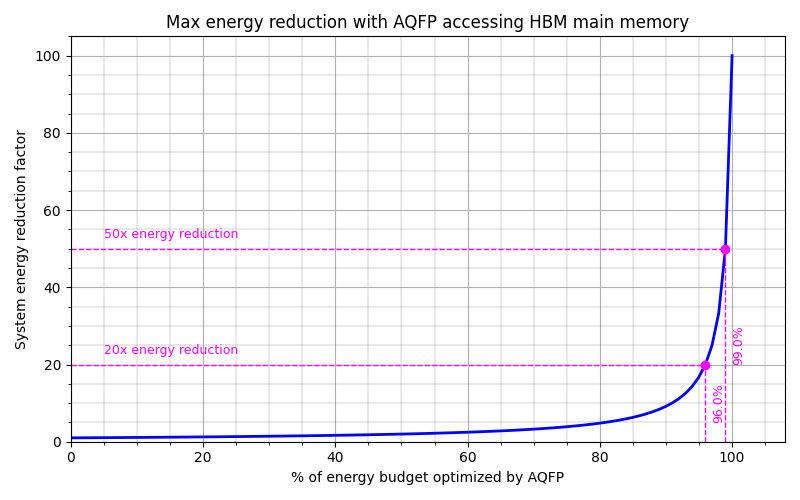
AQFP capable of at least 15.7x system energy reduction on GPT3 prefill workload
All architectures (thermally) fit in small cryostat






Future work: Clock domain crossing (CDC)
Future work: system-scale AQFP
Future work: Cryo-rack design study

AQFP technology now has
- a clock synchronizer
- a 450× denser AQFP register file
- 1.66 b/mm2 previous work → 760 b/mm2 SR-Loop v2
- a high throughput (1 op/cycle) matrix-multiply accelerator
- an architecture design exploration tool for modeling full-stack systems
- a path towards AQFP cryo-rack system with up to 88× energy reduction on today's AI workloads
Thank you!!

Thank you!!

Thank you!!

Additional slides
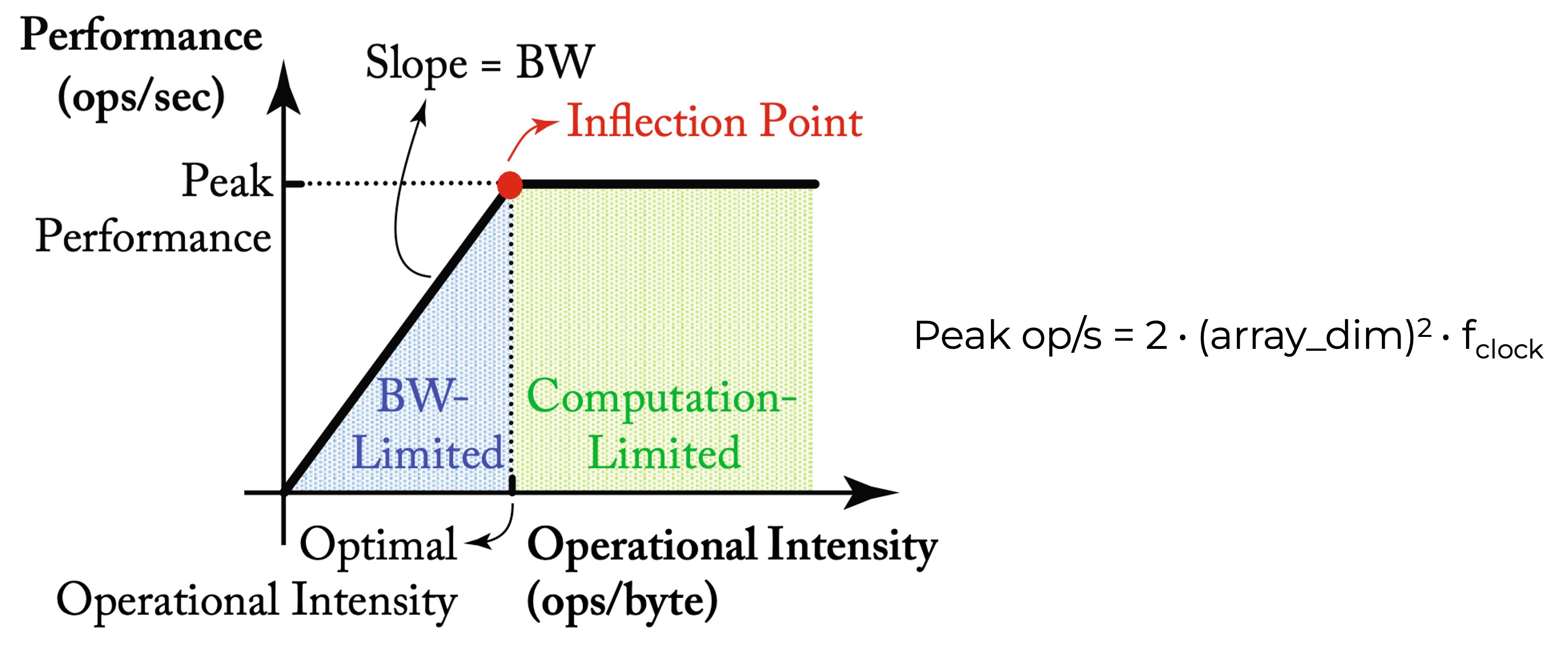
Roofline model
Amdahl's law for energy reduction
Josephson junction overview
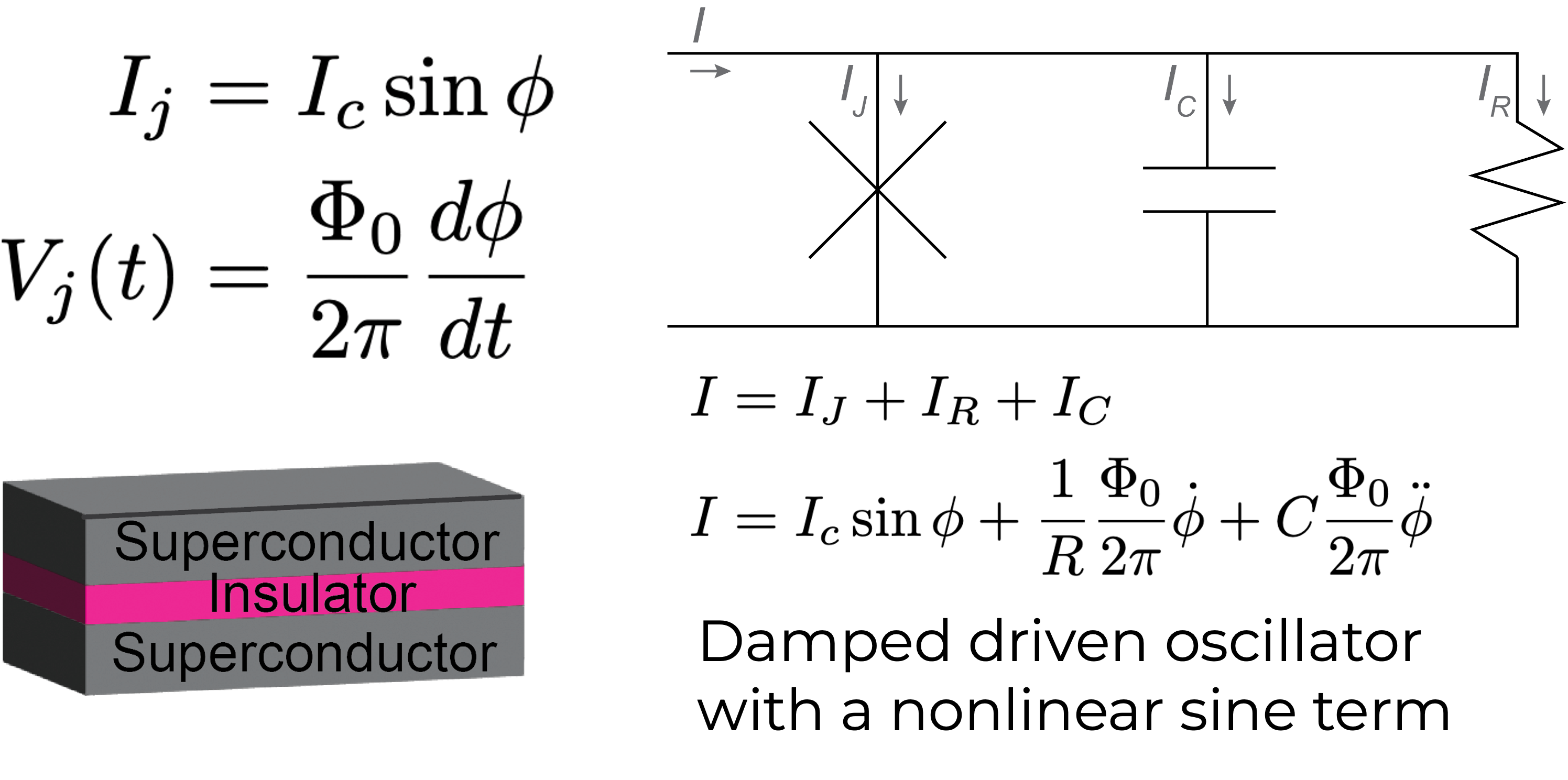
the path to Adiabatic Quantum Flux Parametrons . . .
1959 Parametron Computer: MUSASINO-1

Von Neumann 1954 posthumous patent on majority-gate logic
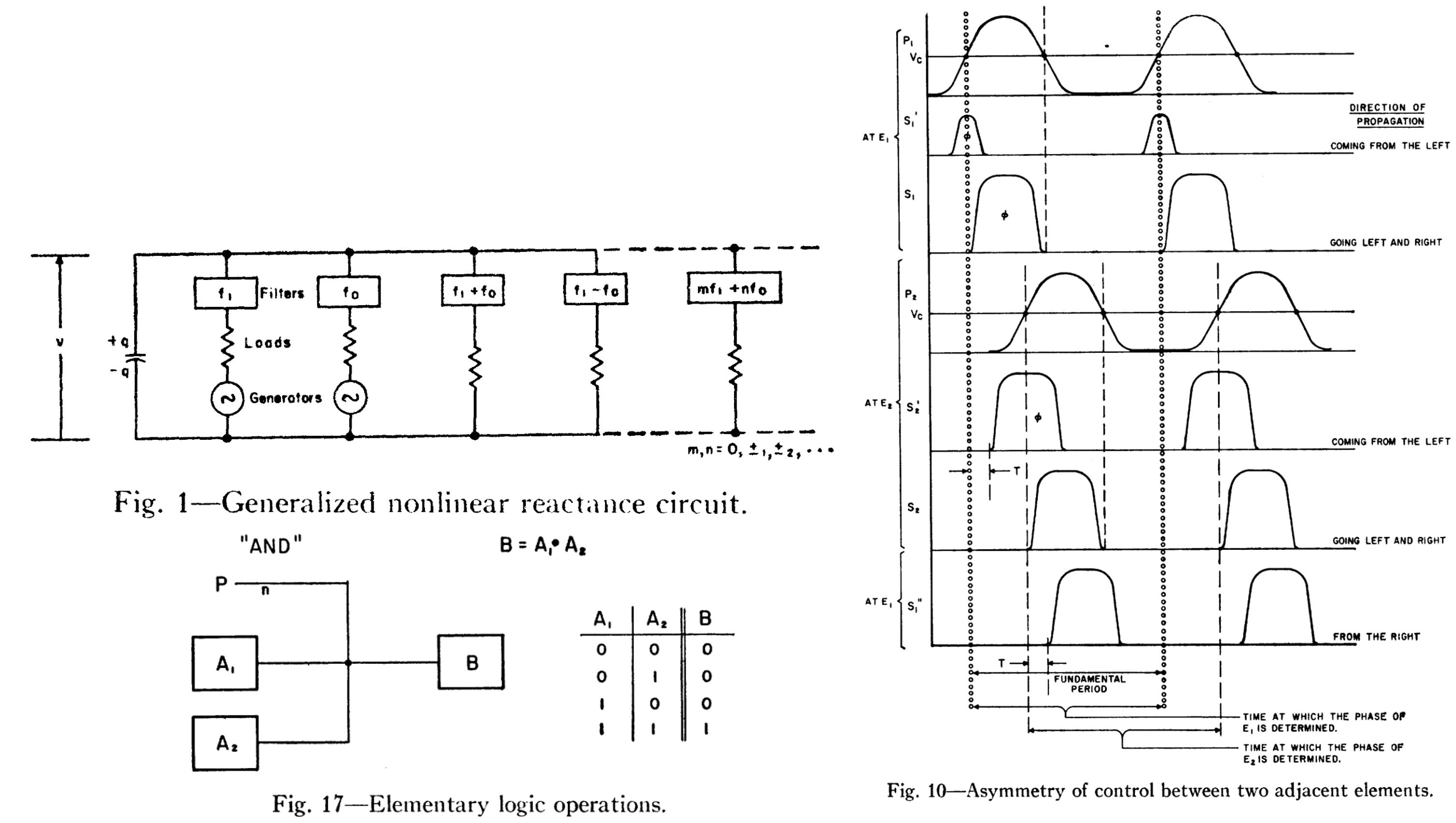
Quantum Flux Parametron (1991)
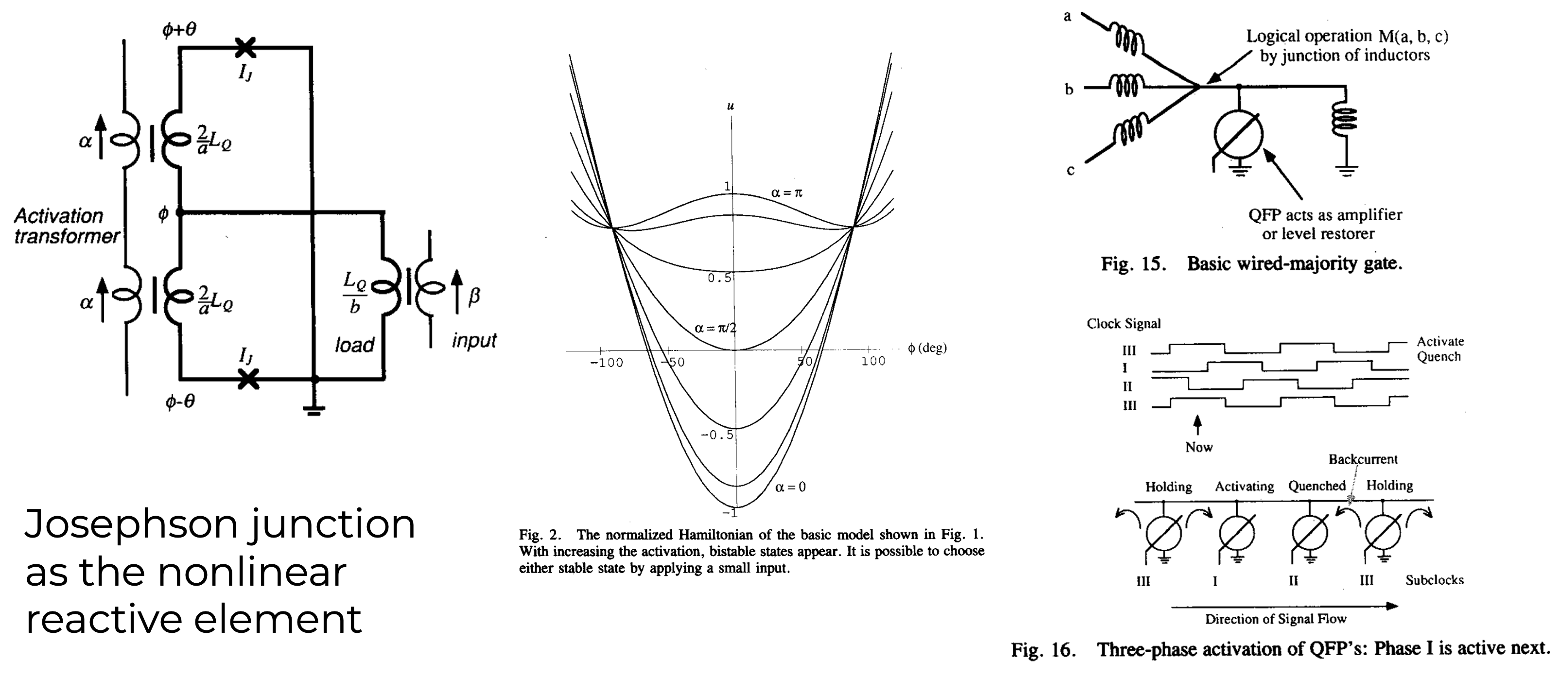
Adiabatic Quantum Flux Parametron (2013)
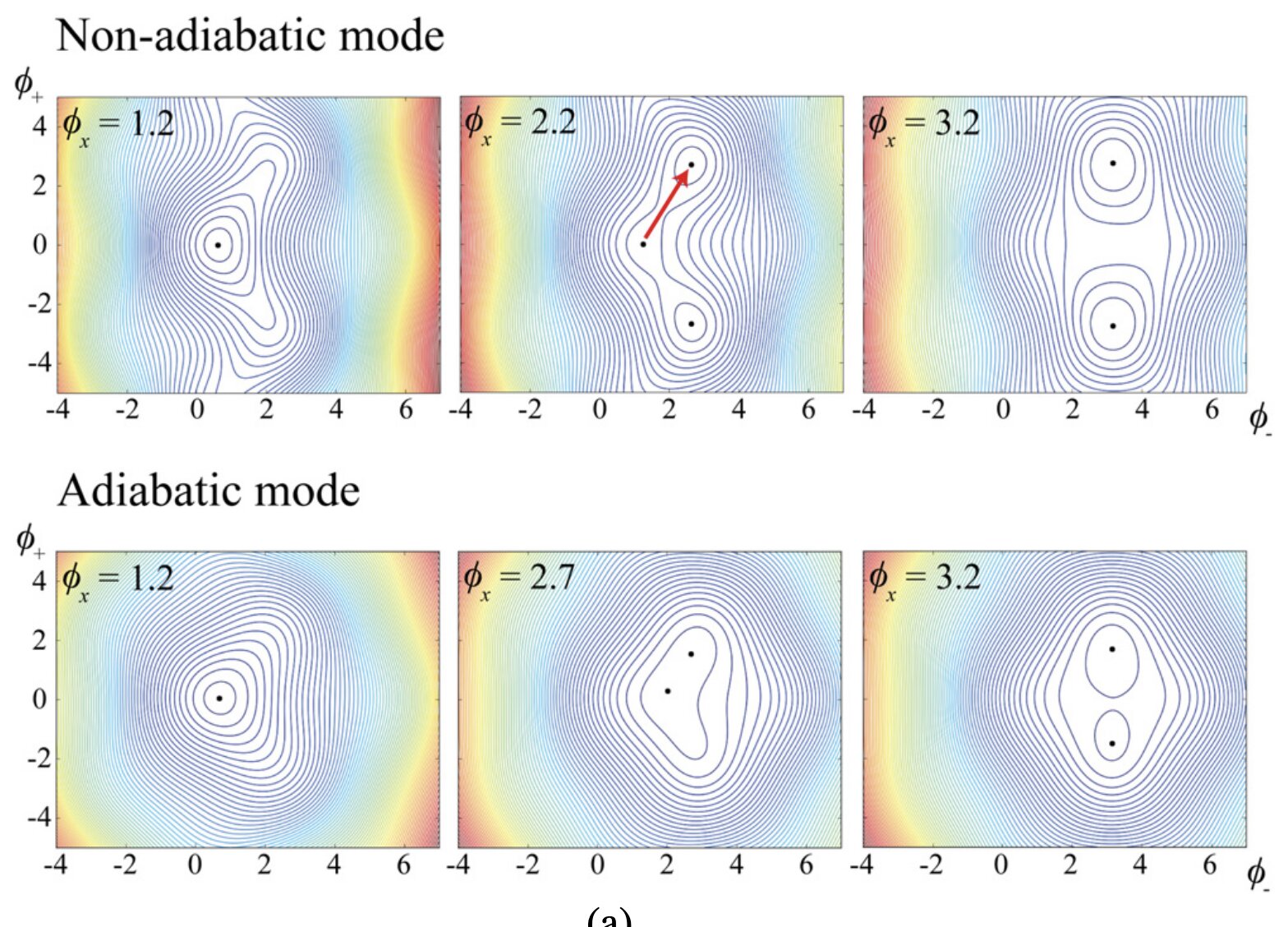
Theoretical limit for irreversible compute